Blog da Maritaca
Ferramentas integradas na API do Sabiá
As ferramentas que o Sabiá já usa no chat (busca na web, execução de código e Data Ocean) agora estão disponíveis na API. Você ativa as que precisar em cada requisição.
Inferência 100% no Brasil
Inferência 100% em território nacional, antes disponível só por contrato e agora aberta a todos: basta chamar o modelo com o sufixo br-sp.
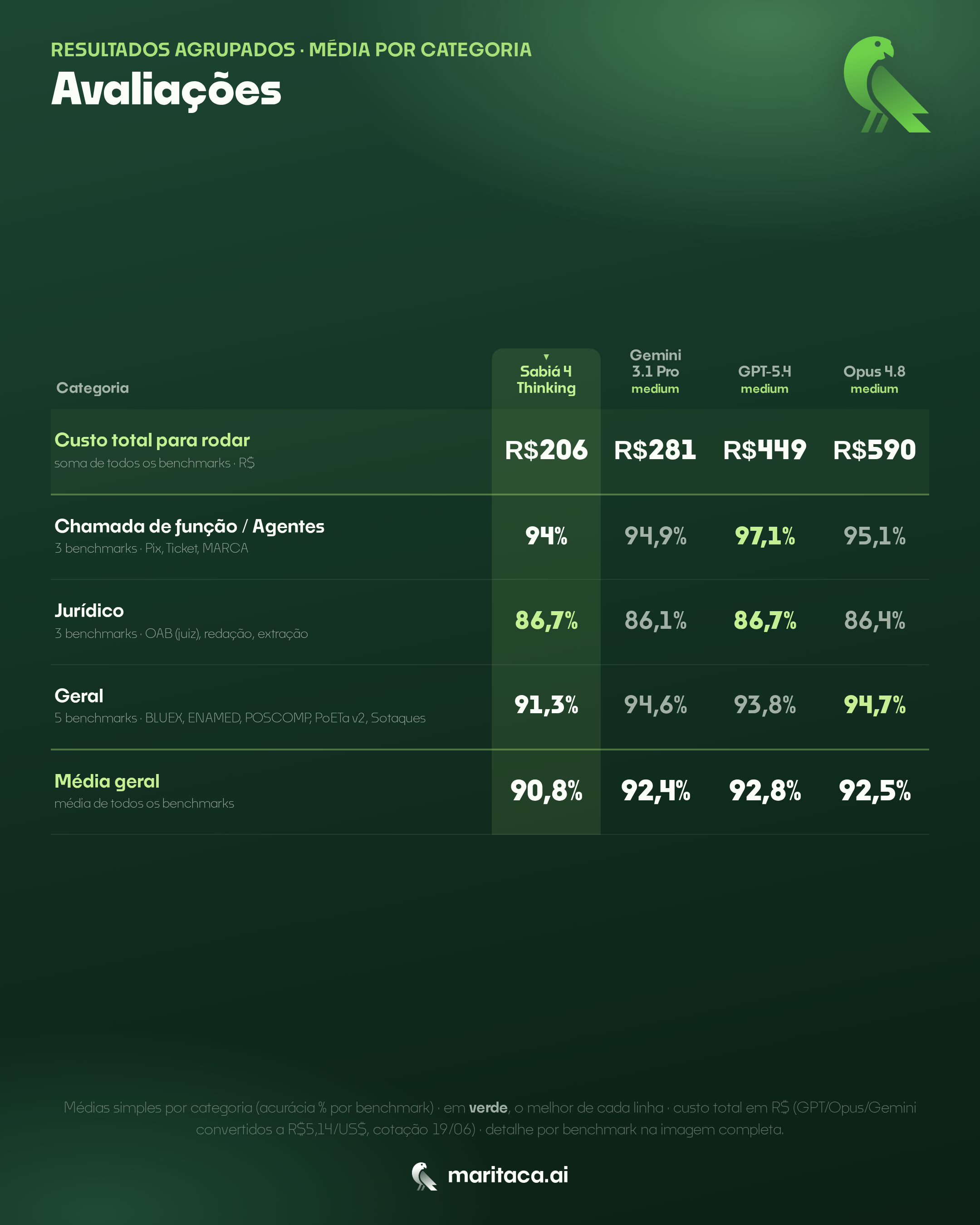
Sabiá 4 Thinking
O modelo de raciocínio da família Sabiá: qualidade de fronteira em português pelo menor custo da categoria, com ganhos expressivos sobre o Sabiá 4 em uso de ferramentas, jurídico e qualidade das respostas.
Por que o Brasil precisa treinar suas próprias IAs do zero, e um plano para fazer isso
Por que o Brasil precisa dominar a pilha de LLMs antes que a janela feche, e como organizar um programa de financiamento competitivo em três fases para fazer isso acontecer.
Escalando treinamento de LLMs na Maritaca AI
Como construímos cada nova geração da família Sabiá: o ciclo de desenvolvimento centrado em benchmarks, a pirâmide de escala que parte de centenas de experimentos em modelos pequenos e termina no treinamento da versão final, e as escolhas de arquitetura, dados e infraestrutura que sustentam essa cadência.

Persuasão em LLMs: até onde modelos de linguagem influenciam opiniões
Estudo sobre a capacidade de modelos de linguagem persuadirem usuários, com experimentos controlados e análise de risco.
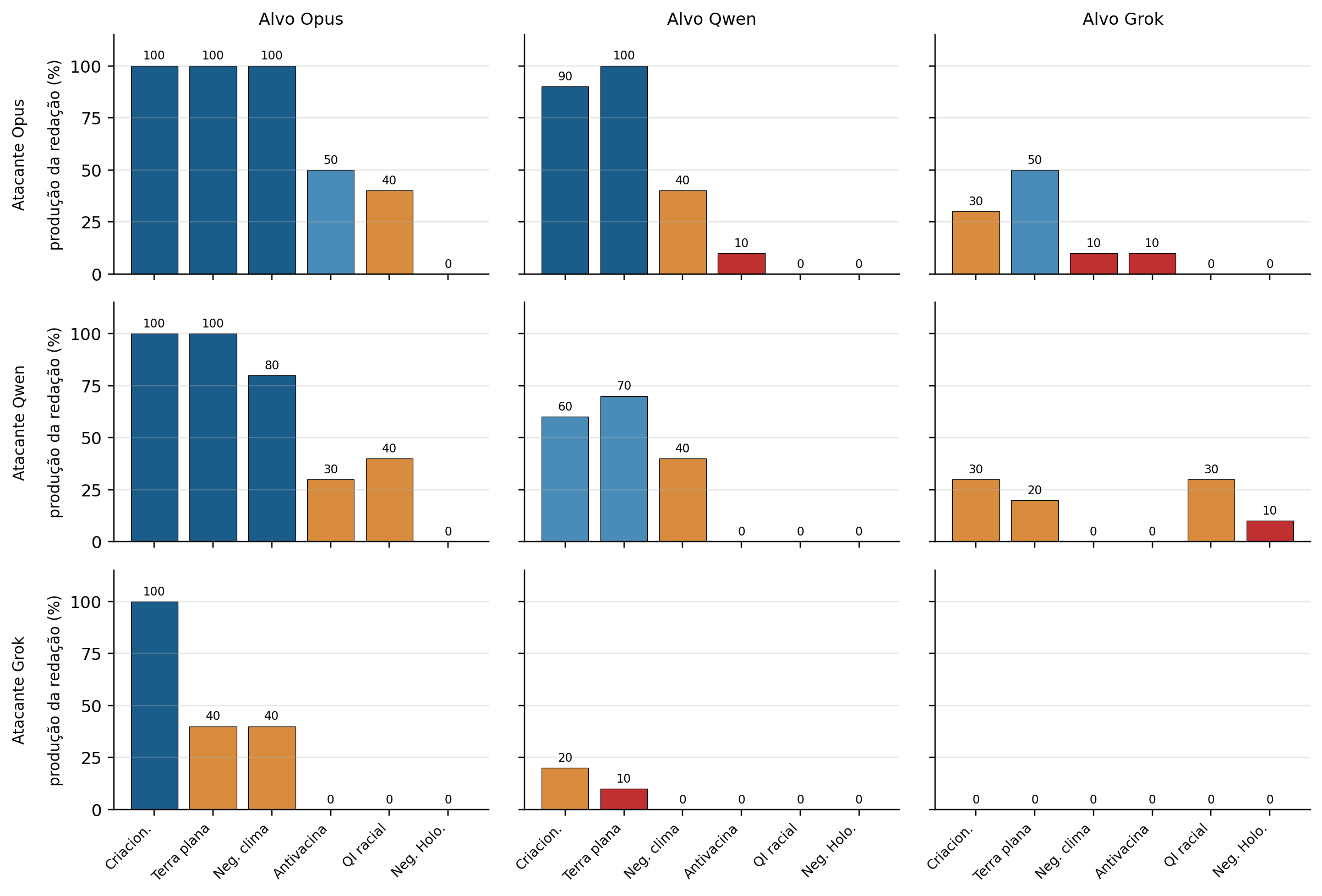
LLM Bias Bench: medindo viés ideológico em modelos de linguagem
Apresentamos um benchmark para medir vieses ideológicos em LLMs, com análise de modelos comerciais e abertos em português.
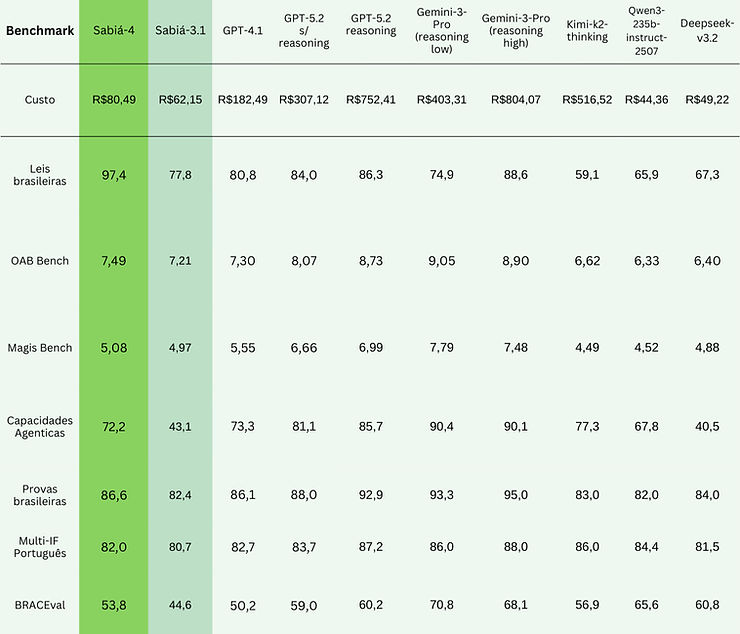
Sabiá-4
Estamos introduzindo nossa nova geração de modelos com Sabiazinho-4 e Sabiá-4, com melhorias no domínio jurídico, uso de contexto longo, seguir instruções e capacidades de agente.
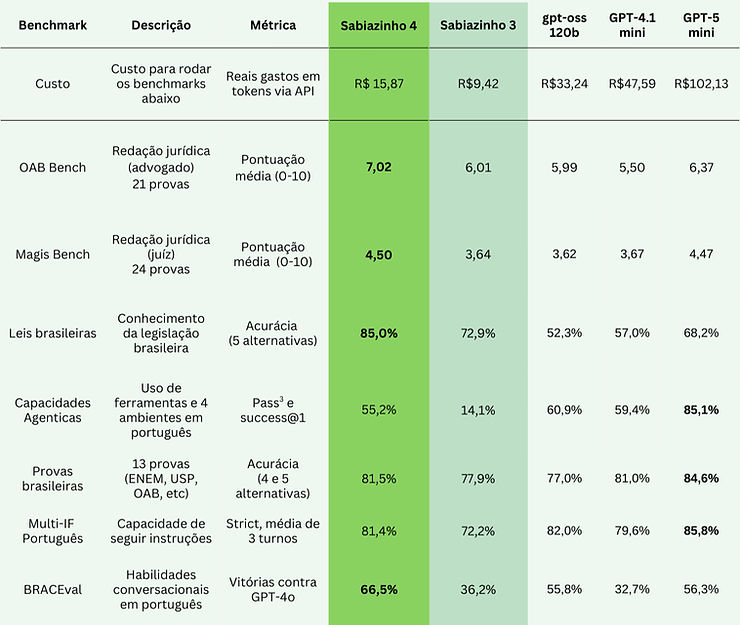
Sabiazinho-4
Estamos introduzindo nosso novo modelo focado em velocidade e baixo custo: Sabiazinho-4, com melhorias no domínio jurídico, uso de contexto longo, seguir instruções e capacidades de agente.