Por que o Brasil precisa treinar suas próprias IAs do zero, e um plano para fazer isso
Por que o Brasil precisa dominar a pilha de LLMs antes que a janela feche, e como organizar um programa de financiamento competitivo em três fases para fazer isso acontecer.
por Rodrigo Nogueira
Um pouco do meu background
Sou Rodrigo Nogueira, CEO e fundador da Maritaca AI, empresa especializada em treinar LLMs relevantes para o Brasil. Sou doutor em ciência da computação pela Universidade de Nova York e um dos pesquisadores em ciência da computação mais citados do país, segundo o Google Scholar. Esse histórico vem de trabalhos open-source como o BERTimbau, de pesquisa pioneira no uso de modelos de deep learning como BERT (hoje considerado um Small Language Model) no campo de recuperação de informação, e mais recentemente do treinamento dos modelos da família Sabiá (Sabiá-1, Sabiá-2, Sabiá-3, Sabiá-4) e de diversos benchmarks que publicamos ao longo dos anos. Se quiser conhecer melhor nosso trabalho, veja a página de pesquisa da Maritaca e o post Escalando treinamento de LLMs na Maritaca AI, onde explico em detalhe como desenvolvemos modelos de IA aqui dentro.
Os avanços recentes em modelos de linguagem, somados a conversas com a comunidade acadêmica e com lideranças políticas e empresariais do país, me motivaram a escrever este documento. Apesar de extenso, tento respaldá-lo na visão de quem está na linha de frente, de quem vai sentir primeiro o que Dario Amodei, CEO da Anthropic, chamou de banho de sangue iminente no mercado de trabalho, e na inação da liderança econômica, política e intelectual brasileira diante do que está vindo.
O impacto que a IA vai trazer no mundo
Os ganhos de capacidade dos modelos de fronteira nos últimos dois anos foram extraordinários, e as medições objetivas dão a melhor noção da escala.
Segundo medições do METR.org, os melhores modelos hoje, como o Claude Mythos (ainda disponível apenas para uma dezena de empresas, mais sobre isso adiante), conseguem completar de forma autônoma tarefas de programação que levariam mais de 10 horas para um programador experiente humano.
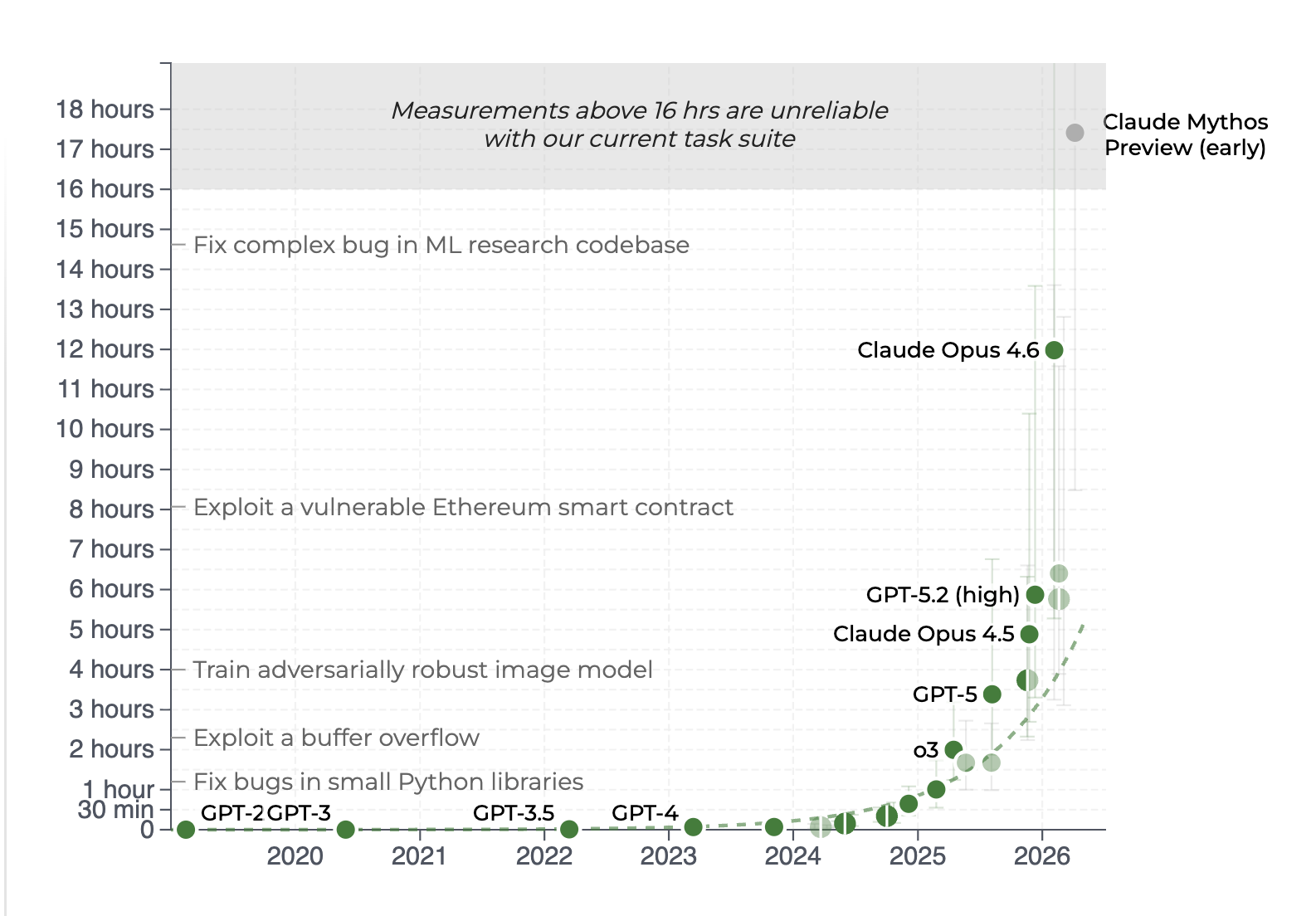
Em outro estudo, o AI Security Institute do Reino Unido mostra que o comprimento das tarefas de cibersegurança que modelos de fronteira conseguem completar vem dobrando a cada poucos meses, e essa taxa só acelerou: modelos recentes ultrapassaram a tendência anterior do próprio estudo.
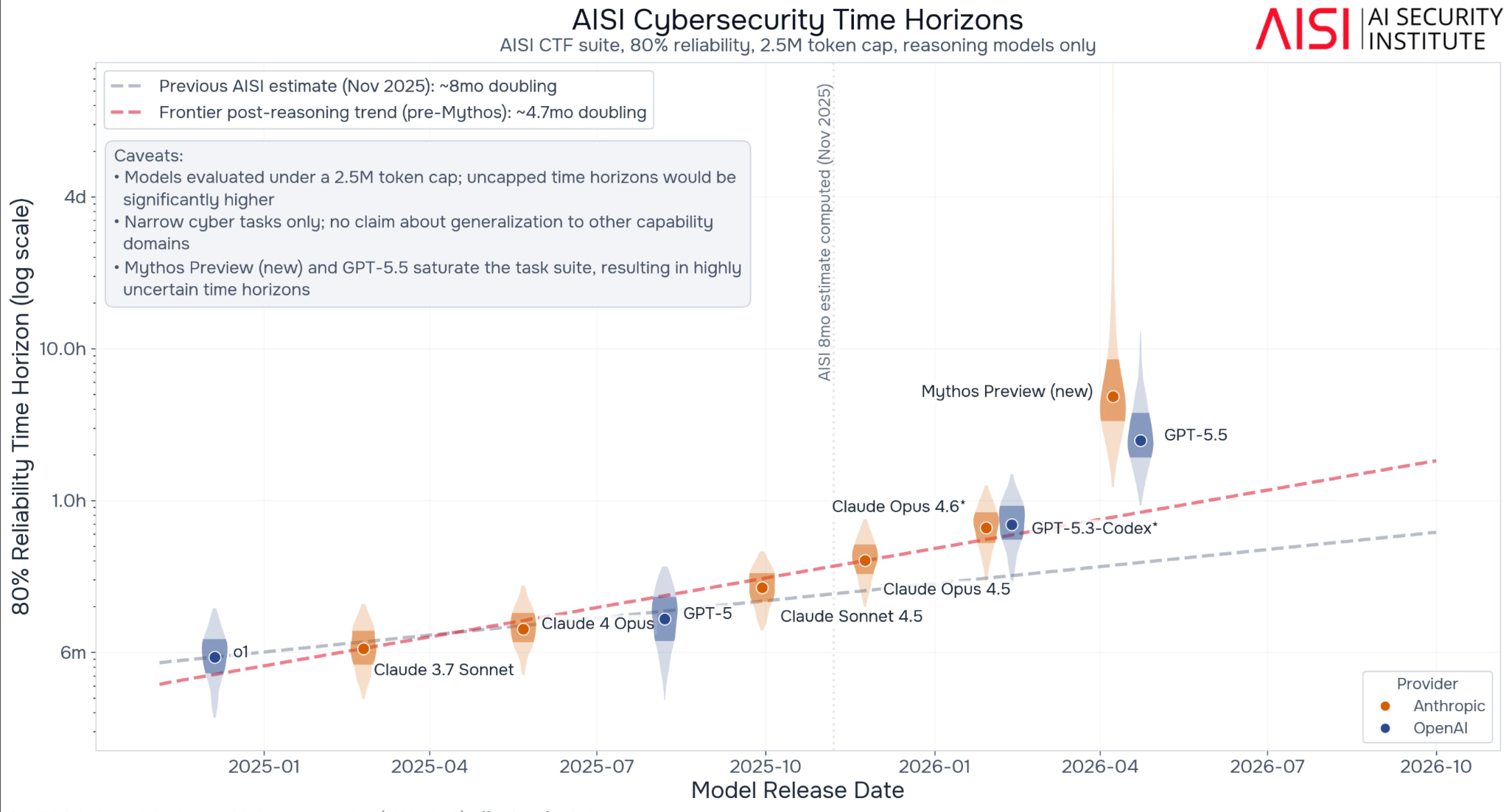
E esses ganhos de produtividade não aparecem apenas em benchmarks. Aparecem em aplicações reais. A Mozilla, por exemplo, publicou que, graças ao Mythos, o número de vulnerabilidades corrigidas no Firefox saltou de patamares de 20 a 30 por mês para 423 só em abril de 2026.
E não é só código. Em março de 2026, o GPT-5.4 Pro foi a primeira IA a resolver um problema da lista do Erdős que estava em aberto desde 2019, com verificação independente pela Epoch AI. Em abril, o mesmo modelo resolveu em 80 minutos, a partir de um único prompt, um problema que vinha resistindo à comunidade matemática há 60 anos. O Fields Medalist Terence Tao classificou a contribuição como “uma extensão significativa da anatomia dos inteiros, que vai muito além da resolução daquele problema específico de Erdős”. Desde o Natal de 2025, 15 problemas em aberto foram resolvidos na matemática; em 11 deles a IA teve participação direta. As IAs deixaram de ser uma ferramenta auxiliar e passaram a contribuir com produção científica de fronteira.
Talvez o sinal mais direto de impacto econômico venha do GDPval, benchmark da OpenAI que mede o desempenho de IAs em tarefas reais extraídas do trabalho de profissionais experientes em 44 ocupações (advogados, engenheiros, médicos, contadores, programadores, designers, enfermeiros etc.) distribuídas em 9 setores que somam US$ 3 trilhões em remuneração anual. Diferente de provas acadêmicas, cada item do GDPval é um entregável real (documento, planilha, slide, esquema), avaliado às cegas por profissionais com média de 14 anos de experiência. Os modelos de fronteira já chegam perto do teto: o GPT-5.5 atinge 84,9% e o Claude Opus 4.7 fica em torno de 80%. Nesses patamares a IA empata ou supera o profissional humano em parcela substancial das tarefas. O efeito é imediato sobre qualquer ocupação que passe a maior parte do dia diante de um computador, os chamados knowledge workers: advogados, contadores, analistas financeiros, jornalistas, gerentes, engenheiros de software, designers.
Na própria Maritaca, 100% do nosso código é hoje escrito por IAs, e o laço de desenvolvimento (orquestração de experimentos, definição de hipóteses promissoras) é em parte conduzido com ajuda de IA também.
Se apenas algumas empresas escolhidas pela Anthropic podem se beneficiar dessas capacidades, o que nos resta como país? Terceirizar a inteligência artificial, que vai gerar boa parte do capital intelectual dos países nos próximos anos, parece uma operação de risco altíssimo, dado o poder que isso confere a quem detém a tecnologia.
Por ser uma operação tão intensiva em capital, é possível que poucas empresas no mundo consigam treinar LLMs de fronteira. O Brasil, com mais de 200 milhões de habitantes e figurando entre a sétima e a décima economia do mundo (dependendo do ranking), deve se posicionar como alternativa às IAs chinesas e americanas. Quando as empresas chinesas pararem de publicar modelos open-weights (mais sobre isso adiante), o que faremos? Vamos depender dessas poucas empresas de fronteira para nos fornecer a inteligência?
Deixaremos IAs estrangeiras:
- escreverem partes de nossas decisões judiciais (Resolução CNJ nº 615/2025 autoriza LLMs a redigir minutas, e o TJSP já tem em produção o “Gerador de Ementas”, baseado em Azure OpenAI);
- analisarem prestações de contas e auditarem o gasto público (o TCU já desenvolveu o ChatTCU baseado em LLMs estrangeiros);
- decidirem quem recebe linhas de crédito;
- definirem planos eleitorais e estratégias de campanha;
- auxiliarem decisões econômicas e de produção em órgãos do governo e em empresas;
- definirem políticas públicas em saúde, segurança e educação;
- triagem em hospitais públicos e atendimento ao cidadão;
- moderarem o que pode ou não circular nas redes sociais brasileiras.
Na primeira desavença política, um ditador ou um presidente autoritário pode ameaçar cortar o fornecimento dessas IAs para o Brasil. E, se o mundo voltar a ser bipolar, teremos que recorrer ao outro lado, que, sabendo que não temos alternativa, vai extrair o máximo possível nas negociações. Se tivermos versões alternativas aqui, mesmo que não estejam na fronteira, teremos muito mais cartas para negociar.
Modelos open-weights vs comerciais
Você pode estar se perguntando: mas por que eu preciso me preocupar com isso, se temos modelos open-weights e eu posso rodá-los ou fazer finetuning localmente?
Hoje essa corrida tem só dois cavalos na frente: OpenAI e Anthropic, com um terceiro logo atrás (Google), e uma multidão de empresas, incluindo as open-weights chinesas, tentando se aproximar. Mas o gap não está fechando. Vejamos os dados.
O gap de qualidade
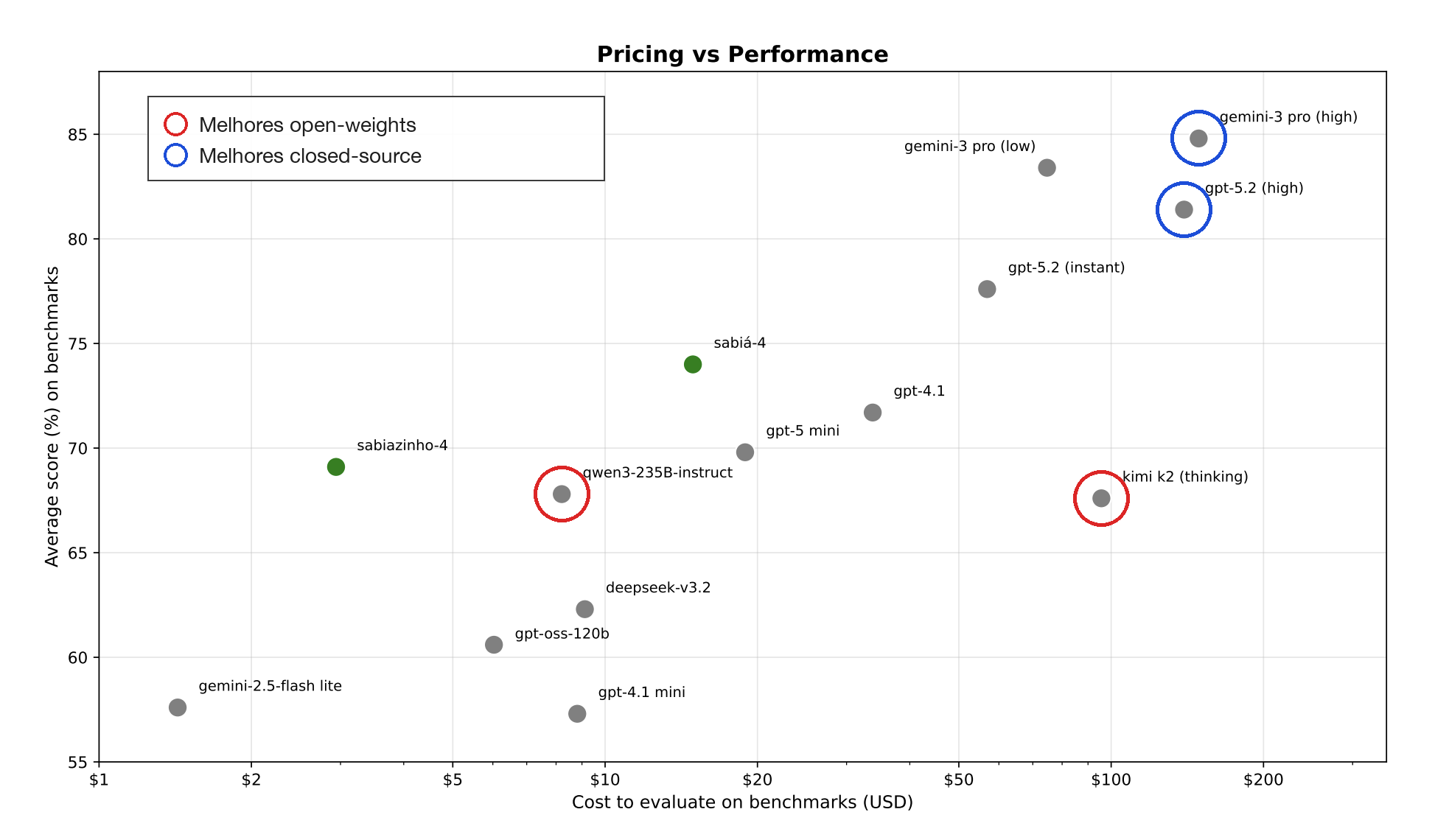
Na Maritaca avaliamos muitos modelos de linguagem, comerciais e open-weights, em uma série de benchmarks que cobrem capacidades relevantes para nossos clientes: análise de múltiplos documentos, navegação na web, conhecimento sobre geografia, história, economia, medicina, elaboração de peças jurídicas, entre outras. A figura abaixo, extraída do relatório técnico do Sabiá-4, mostra o gap entre modelos comerciais closed-source (família GPT, Gemini) e os melhores open-weights de fronteira (Kimi K2, Qwen3-235B): apesar do progresso, os open-weights estão claramente atrás.
E não foi só o nosso estudo a chegar nessa conclusão. O Center for AI Standards and Innovation (CAISI) mostrou que o gap entre open-weights e comerciais não está estreitando: está aumentando.
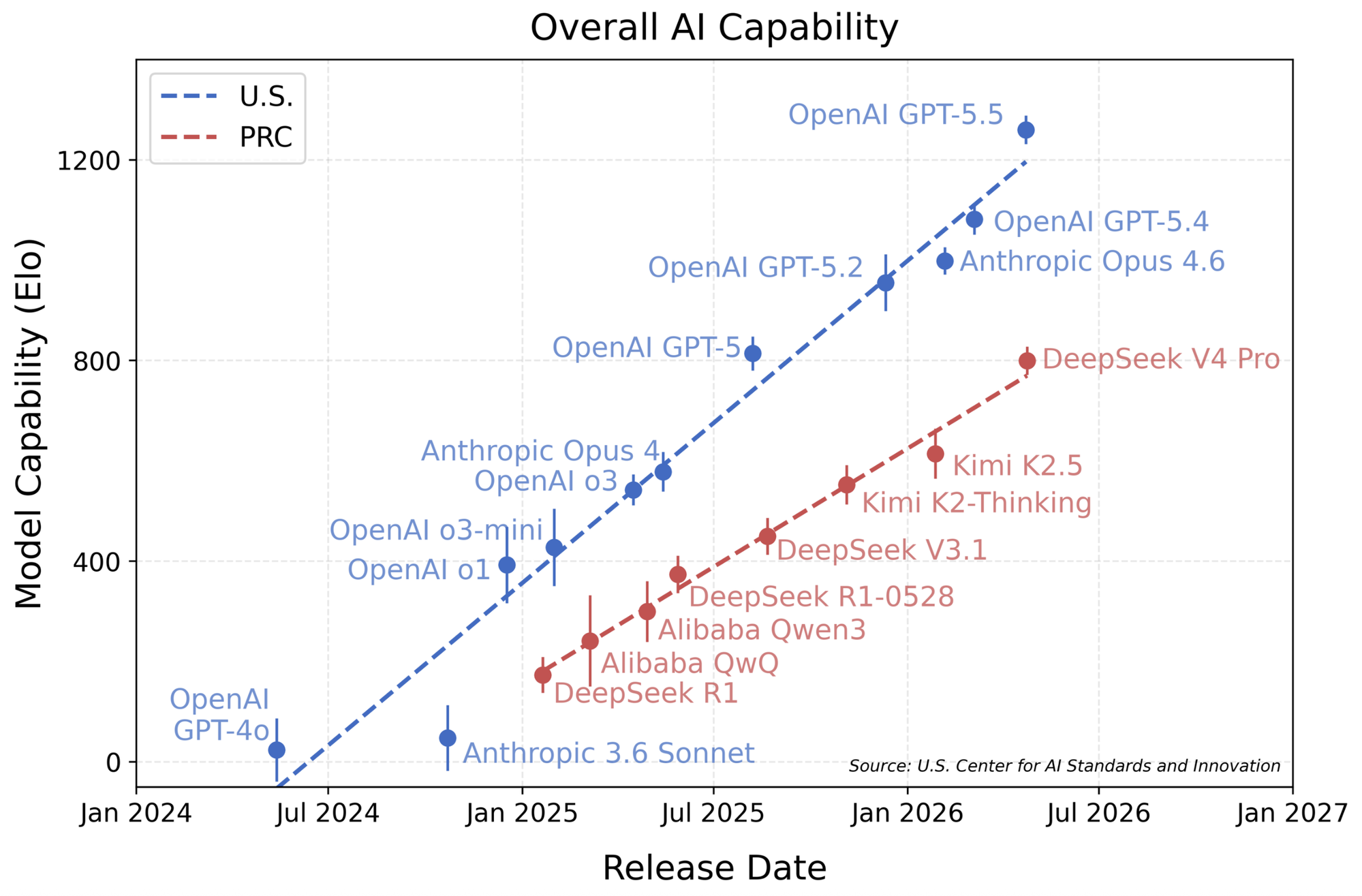
Também observamos algo importante: o desempenho real dos modelos open-weights, medido em benchmarks externos, tende a ficar bem abaixo do desempenho anunciado pelas próprias empresas. O gráfico abaixo torna isso explícito. No painel da esquerda, com base nos benchmarks reportados pelo próprio relatório oficial do DeepSeek, o modelo aparece em patamar comparável a closed-source de fronteira como o Claude Opus 4.6. No painel da direita, em um estudo externo do CAISI rodado em benchmarks internos (não conhecidos previamente pelas empresas), o DeepSeek V4-Pro-Max, hoje o melhor open-weights da fronteira, exibe um gap claro em relação ao Claude Opus 4.6 e ao GPT-5.4.
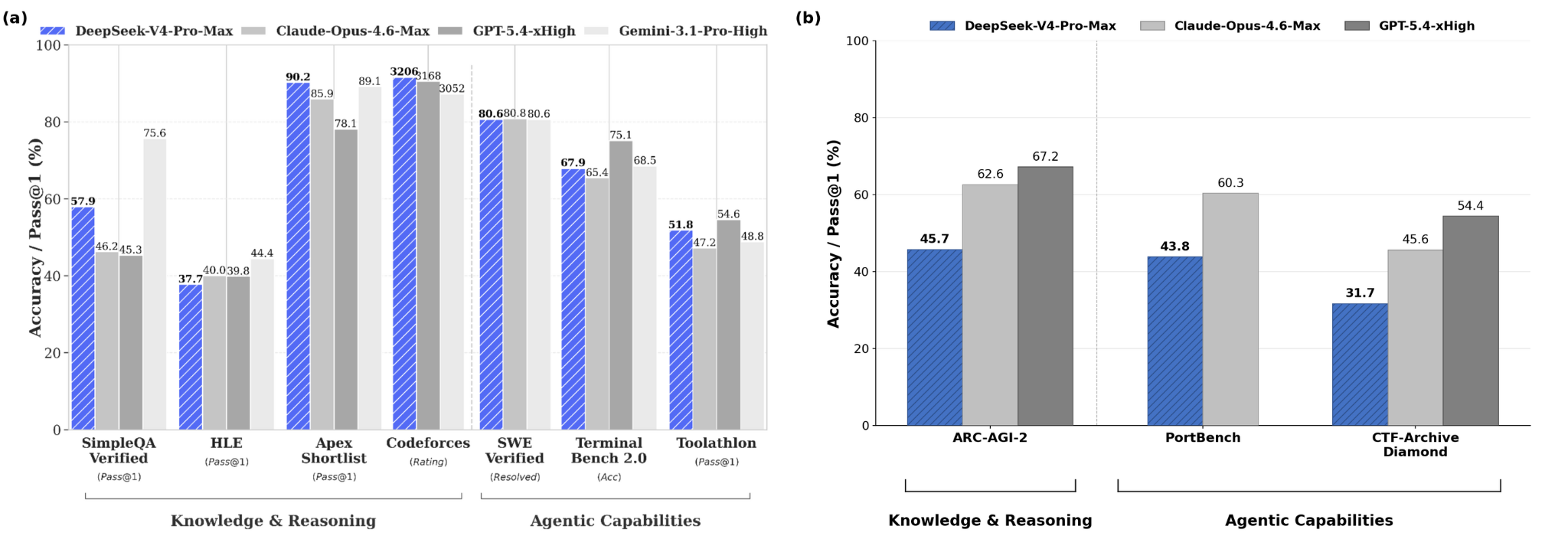
Então se a gente depender de modelos open-weights para desenvolver nossa indústria, vamos partir de uma inteligência de qualidade inferior, e por consequência, ter produtos de qualidade inferior.
Cada vez menos candidatos na fronteira
Há um problema ainda maior: o que temos observado nos últimos anos é que menos candidatos sérios a modelos open-weights estão aparecendo na fronteira. Há dois ou três anos, tínhamos uma constelação razoável de concorrentes: Mistral, Llama, Qwen, Yi, DeepSeek. Mistral, Llama, Qwen e Yi não publicam mais seus melhores modelos abertamente. O Qwen3.6 open-weights, por exemplo, saiu apenas na versão de 35B, que estimamos ser comparável ao GPT-5-nano, o menor e mais fraco dos modelos da família GPT-5.
Modelos como GLM, Kimi e Minimax ficam bem a dever em qualidade nos benchmarks que avaliamos, apesar de anúncios dizendo que competem com GPT-5.5. Não me entendam mal: esses modelos não são ruins, e as empresas não estão trapaceando. É apenas que garantir generalização é difícil. Generalização aqui é o termo de aprendizado de máquina para a capacidade de um modelo manter bom desempenho em condições (tarefas) diferentes daquelas em que foi originalmente treinado. Modelos que passam em testes de generalização são os preferencialmente adotados por usuários e empresas. A exceção, hoje, é o DeepSeek V4, que, segundo nossos testes, mantém generalização razoavelmente melhor que os outros open-weights, embora ainda longe dos três modelos de fronteira.
Quem domina o uso real
Para estimar quais modelos são realmente usados no mundo, podemos olhar para o OpenRouter. Para quem não conhece, o OpenRouter é uma plataforma de roteamento que dá acesso unificado, via uma única API, a centenas de modelos de dezenas de provedores (OpenAI, Anthropic, Google, DeepSeek, Qwen, Mistral, xAI, e por aí vai). Por concentrar o tráfego de milhares de desenvolvedores e produtos, o ranking público do OpenRouter funciona como um termômetro razoavelmente confiável de qual modelo está sendo efetivamente consumido hoje.
E o que esse termômetro mostra? Quem domina o tráfego são OpenAI, Anthropic e Gemini. Os quatro primeiros colocados são closed-source e, mesmo custando algumas vezes mais por token do que seus competidores open-weights, dominam o uso com mais de 65% do market share. Vale notar que o OpenRouter é uma estimativa focada no mercado ocidental e pode não refletir bem o uso por grandes empresas, que tipicamente fecham contrato direto com o provedor. Mas, mesmo com essas ressalvas, o sinal é forte.
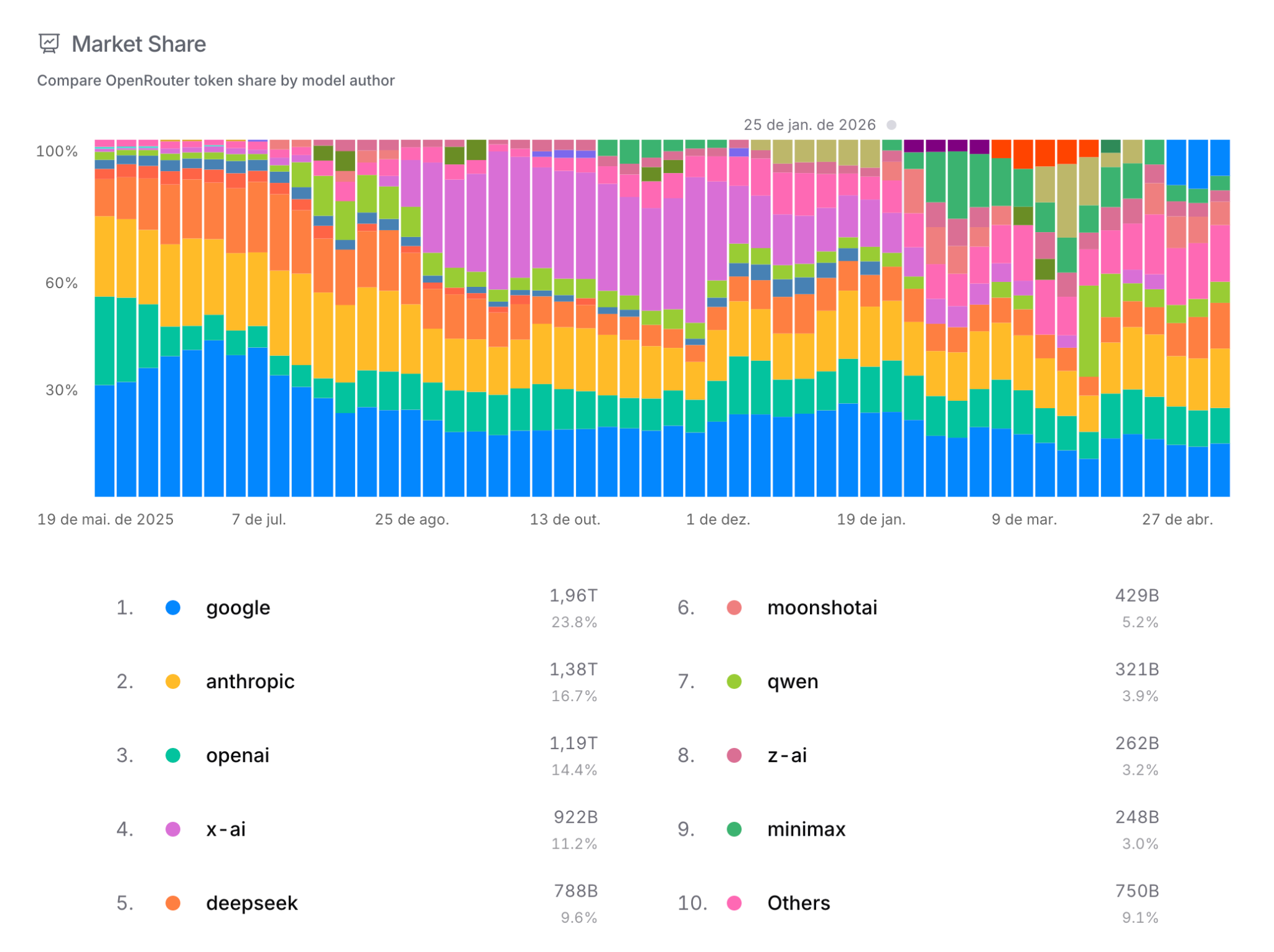
A mensagem é: se você quiser realmente se livrar da dependência dessas três empresas, vai precisar finetunar um modelo open-weights você mesmo. Essa tarefa não é fácil, e é nela que somos especializados na Maritaca. Vamos discutir a seguir o que isso envolve.
Treinar do zero vs finetuning
Antes de continuar, uma definição: ao longo deste documento uso finetuning no sentido amplo, ou seja, qualquer procedimento que altere os pesos de um modelo já existente, seja por pré-treino continuado, por SFT (supervised fine-tuning) ou por aprendizado por reforço. Em alguns lugares o termo é usado de forma mais restrita (só SFT), mas aqui ele cobre todo o pipeline de pós-treino aplicado sobre um checkpoint open-weights.
Conceitualmente, fazer finetuning e treinar do zero diferem em escala e diversidade, não em pipeline.
No pré-treino, você precisa coletar dados diversos do domínio que quer ensinar ao modelo. Em seguida, precisa de SFT (supervised fine-tuning) em dezenas ou centenas de subtarefas para que o modelo se torne generalizável, ou seja, tenha bom desempenho em casos ligeiramente diferentes dos vistos no treino. Essa diversidade é o que traz generalização. Por fim, qualquer laboratório de IA que almeje estar na fronteira precisa de uma grande diversidade de ambientes de aprendizado por reforço. De novo: diversidade é a chave.
Fazer finetuning de open-weight é, basicamente, reproduzir esse pipeline em escala menor.
| Estágio | Treinar do zero (fronteira) | Finetuning de open-weights | ||
|---|---|---|---|---|
| Tokens | Custo em computação | Tokens | Custo em computação | |
| Pré-treino | 10–30 trilhões | US$ 100M a 1B+ | 100B a 1T | US$ 1M a 10M |
| SFT | 10B a 100B | US$ 1M a 10M | 1B a 10B | US$ 50K a 500K |
| Aprendizado por reforço | 100B a 1T (rollouts) | US$ 10M a 100M+ | 10B a 100B (rollouts) | US$ 500K a 10M+ |
Tabela 1: ordens de grandeza para cada etapa do pipeline. Valores variam conforme arquitetura, infraestrutura disponível, eficiência de paralelização e quantidade de iterações necessárias para acertar o treino. Estimativas baseadas em preços spot e on-demand de neoclouds em maio de 2026.
A mensagem é: mesmo com LLMs open-weights disponíveis, eles são de qualidade inferior, e fazer finetuning competitivo deles exige expertise grande.
E, como a tabela acima mostra, o custo de treinar um modelo do zero é da ordem de centenas de milhões a bilhões de dólares. Uma nota importante: muita gente acredita que, por causa do artigo do DeepSeek dizendo que dá para treinar um LLM com US$ 5M, conseguiria fazer o mesmo. No nosso post sobre escala de treinamento, mostro que precisamos treinar modelos menores algumas centenas (às vezes milhares) de vezes até dominar todos os estágios da técnica. Somando tudo, e considerando que é provável que você não acerte o treino do modelo maior de primeira, o custo vai para a ordem de centenas de milhões ou bilhões de dólares.
Vale ainda perguntar: quem tem fôlego financeiro para gastar esse dinheiro todo em nome da ciência? Certamente não o hedge fund que sustenta o DeepSeek. É provável que eles tenham de traçar um plano comercial em breve para tornar a operação rentável, antes que ela seja cortada. Não é uma questão de se os modelos open-weights de fronteira vão se esgotar, é uma questão de quando.
Espero ter convencido você, até este ponto, da importância de termos uma IA própria e de dominar essa pilha. Se ainda não acha relevante, peço que pelo menos veja o plano de ação a seguir. Você vai notar que a verba proposta não chega a uma fração da verba dedicada hoje a editais da FINEP para aplicação de LLMs, que geralmente não resultam em produtos comerciais rentáveis.
Plano de ação
O plano a seguir é inspirado no Sovereign AI Foundation Model Project sul-coreano, conduzido pelo MSIT (Ministry of Science and ICT) com orçamento de KRW 213,6 bilhões (~R$ 800M, equivalente a ~US$ 160M) e estrutura de afunilamento: 15 candidaturas iniciais, 5 consórcios selecionados em agosto de 2025 (LG AI Research, SK Telecom, Upstage, Naver Cloud e NC AI), 3 selecionados após a primeira avaliação em janeiro de 2026 (LG, SKT e Upstage), com novas avaliações a cada 6 meses ao longo de até 3 anos. Os times recebem majoritariamente aluguel de GPUs, com verbas adicionais para aquisição e processamento de dados e para contratação de pesquisadores de ponta.
O objetivo é financiar diversas equipes para que tentem treinar LLMs do zero e, progressivamente, reduzir o número de equipes nas fases seguintes, concentrando mais poder computacional naquelas que avançam.
A ideia central do plano é simples: fomentar que vários laboratórios, inclusive a Maritaca, tenham acesso à computação necessária para treinar modelos do zero. Ao final de 1,5 ano, o objetivo não é entregar um modelo que rivalize com GPT-5.5, mas acender a fagulha: formar o corpo técnico, a infraestrutura e o know-how de pré-treino que sustentam uma indústria de IA brasileira. Sem esse empurrão inicial, é improvável que isso aconteça por iniciativa do setor privado. O caminho mais fácil, do ponto de vista de quem busca retorno rápido, é usar modelos open-weights existentes ou construir o que se convencionou chamar de GPT wrappers: produtos que são essencialmente uma interface ou um fluxo de prompts em cima da API da OpenAI, da Anthropic ou do Google, sem nenhum treinamento próprio. Esses produtos podem ser rentáveis no curto prazo, mas dependem inteiramente de quem está na fronteira e desaparecem na hora em que essas empresas mudam preço, política de uso ou termo contratual. Apenas com um empurrão público desse tipo é que conseguimos formar o corpo técnico capaz de fazer pré-treino do zero e garantir que o Brasil tenha alternativas de acesso à IA de fronteira, em vez de negociar em posição estruturalmente desfavorável com as grandes empresas de IA quando o país depender desses serviços e não houver alternativa local.
Uma das inovações deste plano é usar IA para a seleção dos candidatos, inclusive para escolher os membros da própria comissão organizadora. Reconhecemos a contribuição histórica da comunidade acadêmica brasileira em diversas áreas. Mas, para um programa que precisa executar em 1,5 ano disputando com a fronteira internacional, é preciso ser pragmático: a seleção deve favorecer quem está, neste momento, produzindo resultados de ponta em deep learning. Critérios objetivos aplicados por LLMs sobre uma rubrica pública oferecem, na prática, mais transparência e menos espaço para viés do que um processo conduzido por comitês fechados, e o custo de uma escolha errada é alto: um modelo treinado mal pode consumir todo o orçamento sem que se aprenda nada.
Estrutura em três fases
Figura 8: estrutura em três fases. Em cada passagem, a quantidade de equipes cai e a verba por equipe aumenta. Totais por fase: Fase 1: R$ 80M (20 × R$ 4M), Fase 2: R$ 96M (8 × R$ 12M), Fase 3: R$ 90M (3 × R$ 30M). Verba total do programa: R$ 266M ao longo de 1,5 ano.
Custo total do programa: R$ 266 milhões. Vale colocar em perspectiva: é cerca de um quarto dos R$ 1 bilhão originalmente propostos pelo PBIA (Plano Brasileiro de Inteligência Artificial) para o treinamento de um LLM nacional.
O valor de R$ 4M por equipe da Fase 1 foi calculado assumindo 32 GPUs B200 por equipe (a US$ 5/hora, cotação de R$ 5/US$), rodando por 6 meses, ao preço on-demand atual de neoclouds. Mas cada equipe é livre para gastar o dinheiro como preferir.
E é importante que essa liberdade exista, porque nem todo time precisa concentrar a verba em computação. Há equipes que defendem, por exemplo, que um corpus de pré-treino curado por linguistas, em escala menor mas com qualidade muito superior à da web, pode produzir um modelo competitivo na fronteira com bem menos compute. Outras apostam em arquiteturas alternativas, em síntese de dados ou em curadoria humana de tarefas de SFT e RL. Nenhuma dessas hipóteses tem hoje consenso na literatura, e exatamente por isso a Fase 1 é o lugar certo para testá-las: com 20 equipes seguindo estratégias possivelmente distintas, o próprio resultado nos benchmarks vai indicar, empiricamente, qual combinação de compute, dados e algoritmo entrega mais valor por real investido. Forçar todos os times a uma única receita seria abrir mão dessa informação.
Cada fase dura 6 meses, totalizando 1,5 ano de projeto. Por que tão pouco? Manter o cronograma curto, como foi feito no programa sul-coreano, evita caronas que vão querer aprender redes neurais do zero com dinheiro público. Se você não sabe nada e mesmo por sorte foi selecionado, é muito provável que não consiga estar entre as 8 equipes que passam para a segunda fase. Mas se conseguir, ótimo: bom para todos.
Critérios de seleção
Elegibilidade. Antes dos critérios pontuáveis, há um filtro de elegibilidade. A equipe candidata deve atender, no mínimo, a uma das duas condições:
- estar formalmente vinculada a uma instituição brasileira (universidade, instituto, empresa ou startup com CNPJ ativo no Brasil); ou
- ser uma empresa internacional cujo time técnico declarado para o projeto tenha pelo menos metade dos membros brasileiros ou com vínculo de residência no Brasil de no mínimo dois anos.
A justificativa é simples: o programa é financiado com dinheiro público brasileiro para construir capacidade de IA no Brasil. Faz sentido garantir que o conhecimento, o time e a propriedade intelectual produzidos fiquem no país.
A seleção será feita de maneira automatizada, usando três juízes baseados em LLMs de fronteira, para reduzir viés humano. Os critérios principais:
- Número de publicações per capita da equipe na área de deep learning. Os candidatos enviam a lista de artigos, e um LLM open-weights com prompt aberto decide se cada artigo é de deep learning. Artigos com mais de 10 anos não contam. A razão é simples e pragmática: o programa precisa executar em 1,5 ano, em paralelo com modelos comerciais que vêm sendo retreinados a cada poucos meses. A seleção deve privilegiar equipes cuja produção recente (publicações, código, modelos abertos) demonstre domínio do estado da arte. Resultados consolidados há mais de uma década, embora valiosos em outros contextos, são uma proxy fraca da capacidade de competir hoje na fronteira de deep learning.
- Número de citações per capita da equipe em artigos de deep learning, usando o mesmo método de classificação por LLM.
- Estrelas em software open-source publicado no GitHub (ou similar) na área de deep learning.
- Downloads de modelos e/ou datasets abertos publicados na Hugging Face ou repositórios equivalentes.
- Outras evidências de experiência prática em deep learning. Os juízes LLM avaliarão, por exemplo, se o sistema descrito envolve de fato treinamento de redes neurais (prompt engineering não conta) ou medição rigorosa de sistemas de IA.
Importante: as evidências para os itens acima só terão validade se produzidas até maio de 2026. Isso evita que participantes inundem o sistema no último mês com materiais visando rankear melhor. Queremos pesquisadores e desenvolvedores com trajetória comprovada. O programa não pretende entregar R$ 4M a equipes sem experiência prévia em treinamento de redes neurais. O objetivo é apoiar quem, ao longo dos últimos anos, vem produzindo de forma consistente material de qualidade na área.
Critérios de passagem entre fases
Cada equipe da Fase 1 deve produzir:
- Um benchmark original próprio, com métrica única de 0 a 100, em que a diferença de pontuação entre Llama-2-7B e DeepSeek V4 seja de pelo menos 30 pontos. Esse critério evita os dois extremos clássicos que tornam um benchmark inútil: o fácil demais, em que praticamente todos os modelos pontuam perto de 100 e não conseguimos separar capacidade real (acontece, por exemplo, com somas de dois dígitos: até modelos antigos acertam tudo, e o benchmark satura); e o difícil demais, em que o benchmark está tão acima do estado da arte que praticamente todos os modelos pontuam perto de zero, e ainda assim não dá para distinguir quem está melhorando. Em qualquer um dos dois casos o benchmark não tem poder discriminativo: a métrica não diferencia gerações nem qualidade de treino. Exigir 30 pontos de diferença entre um modelo de 2023 e um de 2026 garante que o benchmark mede algo que está, de fato, evoluindo com o estado da arte.
- Resultados em 10 benchmarks públicos definidos pela comissão organizadora, cobrindo tópicos como uso de ferramentas (tool use), conhecimento sobre o Brasil, escrita de redações em português, resolução de tarefas de código, resolução de problemas de matemática, e tarefas que beneficiem o cidadão ou o desenvolvimento do país. Esses benchmarks podem ser em qualquer idioma e a comissão deve priorizar avaliações já consolidadas em leaderboards públicos, como o Artificial Analysis, garantindo comparabilidade com o estado da arte internacional.
Ao final da Fase 1, os modelos das 20 equipes são avaliados nos 20 benchmarks originais produzidos pelas próprias equipes mais nos 10 benchmarks públicos escolhidos pela comissão. A pontuação final de cada equipe é a soma do desempenho nesses 30 benchmarks. As 8 equipes com maior soma avançam para a Fase 2.
A mesma lógica se aplica na passagem da Fase 2 para a Fase 3: cada uma das 8 equipes da Fase 2 produz um novo benchmark original (totalizando 8), que se somam a um novo conjunto de 10 benchmarks públicos escolhidos pela comissão. As 3 equipes com maior soma avançam para a Fase 3.
Prêmio para finalistas
Para fechar o ciclo entre o investimento público inicial e a sustentabilidade comercial das equipes, propomos que as duas melhores equipes ao final da Fase 3 tenham prioridade na contratação para servir modelos de IA ao SERPRO e a outras instituições do governo federal. O setor público é hoje um dos maiores consumidores potenciais de IA no país, abrangendo Judiciário, controle externo, saúde pública, Receita, defesa e diversos órgãos reguladores, e tem necessidade legítima de soberania sobre os modelos que processam dados sensíveis dos cidadãos.
Ao garantir que as equipes vencedoras encontrem um mercado já pronto na saída do programa, o investimento público inicial se converte em demanda recorrente. O governo financia o desenvolvimento da capacidade técnica e, em seguida, usa essa capacidade nos seus próprios sistemas, em vez de seguir dependente de provedores estrangeiros. É o mesmo ciclo virtuoso que sustenta a indústria de IA chinesa e americana: capital público (defesa, ciência, infraestrutura) ancora as primeiras gerações; o mercado privado financia as seguintes.
Confidencialidade do código e auditoria
Uma decisão de desenho importante: os códigos de treinamento e o pipeline de seleção/curadoria de dados das equipes não precisam ser públicos. Eles permanecem privados, protegidos como propriedade intelectual da equipe. O que muda é que esses artefatos serão auditados em sigilo pela comissão organizadora ao final de cada fase, com dois objetivos:
- Garantir que a equipe tem domínio real da pilha de treinamento. A auditoria verifica que existe código próprio funcional para pré-treino, SFT e RL, e que os dados foram efetivamente curados pela equipe, não terceirizados ou copiados sem entendimento.
- Permitir reprodução independente. Um verificador externo, sob NDA, deve conseguir, a partir do código e dos dados auditados, reproduzir os números reportados pela equipe nos benchmarks. Se a reprodução falha por uma margem significativa, a equipe perde pontos ou é desclassificada.
A decisão por código privado, não público, é deliberada e tem um motivo concreto: ela viabiliza a participação de empresas e instituições mais maduras em treino de LLM. A Maritaca, por exemplo, já investiu milhões em desenvolver o pipeline da família Sabiá e não estaria disposta a abrir essa propriedade intelectual como condição de participação no edital. Se forçássemos publicação aberta de todo o código de treinamento, a consequência mais provável seria afastar exatamente quem mais tem capacidade técnica acumulada, e atrair somente equipes com pouca experiência prévia, que têm menos a perder em abrir seu trabalho. O equilíbrio escolhido, auditoria com confidencialidade, mantém a barra técnica alta sem exigir que empresas sérias abram mão de anos de investimento privado.
Há ainda uma dimensão de sustentabilidade econômica que reforça essa escolha. Ao não obrigar as equipes a abrir o código, criamos condições para que delas surjam empresas sustentáveis no longo prazo: o pipeline de treinamento se torna propriedade intelectual e diferencial competitivo, da mesma forma que acontece com OpenAI, Anthropic, Google e DeepSeek. Se forçássemos a abertura integral, esse diferencial desaparece, e nenhuma equipe colocaria seu máximo esforço sabendo que, no dia seguinte ao fim do projeto, um concorrente pode reaparecer apenas reexecutando a receita pública. Essa lógica também reconhece um fato estrutural: o desenvolvimento de IA é um processo contínuo, e não pode ser financiado pelo governo indefinidamente. O investimento público inicial é necessário para o Brasil ter sua primeira geração de modelos treinados do zero, mas as gerações seguintes precisam se sustentar por iniciativa privada e faturamento próprio das empresas que sobreviverem ao programa.
Apelação
Qualquer equipe que se sinta injustiçada pelo julgamento dos LLMs, seja na pré-seleção inicial ou na passagem entre fases, pode apresentar recurso à comissão organizadora. O recurso deve apontar de forma objetiva onde o julgamento automatizado errou: critério mal aplicado, evidência ignorada, ou inconsistência entre os três juízes-LLM. A comissão, definida na seção seguinte com critérios objetivos, faz a análise humana e decide. Decisões da comissão são finais.
Comissão organizadora
A comissão será formada por pessoas que atendam aos seguintes requisitos:
- Tenham mais de 2.000 citações no Google Scholar em artigos relacionados a deep learning, considerando apenas os últimos 5 anos.
- Tenham contribuído com modelos open-weights, código em GitHub, ou datasets/benchmarks públicos de impacto.
O recorte dos últimos 5 anos é deliberado e visa garantir que a comissão seja composta por pessoas com produção atual relevante na área. Não se trata de desconsiderar contribuições anteriores, e vale notar que muitos pesquisadores ativos hoje vêm justamente da tradição acadêmica brasileira. O ponto é prático: deep learning vive uma reconfiguração rápida, com técnicas e arquiteturas mudando a cada 12 a 24 meses. Decisões sobre quem deve receber recursos para treinar LLMs de fronteira pedem avaliadores cuja prática recente os mantenha sincronizados com esse ritmo. O recorte reduz o risco, recorrente em editais brasileiros, de que escolhas técnicas sensíveis fiquem nas mãos de avaliadores afastados da prática atual.
Em resumo: queremos avaliadores com produção recente em deep learning.
Ponto de partida e expectativa para a Fase 1
Vale fazer aqui uma distinção que costuma ser confundida no debate público:
- Open-weights: a empresa libera apenas os pesos do modelo já treinado. Você pode rodar, fazer finetuning ou destilar, mas não tem acesso aos dados de pré-treino, ao código de treinamento, nem ao pipeline de curadoria de dados. É o caso de Llama, Qwen, DeepSeek, Mistral.
- Open-source (de verdade): a organização libera o pacote inteiro. Pesos + dados de pré-treino + código de treinamento + pipeline de curadoria. Você consegue reproduzir o modelo do zero, modificar receitas e entender por que ele se comporta como se comporta. O exemplo de referência hoje é o OLMo 3 do Allen Institute for AI, que publicou dados, scripts de pré-processamento, scripts de pré-treino, scripts de SFT e RL, e todos os logs de execução.
As 20 equipes selecionadas na Fase 1 são encorajadas a partir de receitas open-source como a do OLMo 3, em vez de tentar reinventar todo o pipeline. O conhecimento acumulado pela comunidade nos últimos anos está literalmente disponível em repositórios públicos.
Dado o orçamento de R$ 4M e os 6 meses por equipe da Fase 1, é importante calibrar expectativas: as equipes da Fase 1 não vão produzir modelos de fronteira. Vão produzir modelos pequenos, possivelmente da ordem de poucos bilhões de parâmetros, treinados em corpora modestos. O objetivo dessa fase não é entregar um produto, é aprender a treinar: dominar o ciclo de pré-treino, SFT e RL, internalizar o pipeline de curadoria de dados, encontrar gargalos de infraestrutura, e produzir um benchmark próprio que mostre que a equipe sabe medir o que importa.
O conhecimento acumulado é o que permite que as melhores equipes da Fase 1 cheguem à Fase 2 já com pipeline funcionando, e usem o orçamento maior (R$ 12M) para subir um degrau no tamanho do modelo e na qualidade dos dados. O mesmo vale na transição da Fase 2 para a Fase 3 (R$ 30M por equipe). É um processo cumulativo: cada fase está construindo o corpo técnico que vai sustentar a indústria brasileira de IA nos próximos 5 a 10 anos.
Por que competitivo, não colaborativo
Vale tornar explícito um ponto que diferencia este plano de outras propostas que vêm sendo debatidas no governo. A proposta aqui é, em sua essência, competitiva. Em contraste, têm circulado abordagens colaborativas, em que se reuniria um pequeno grupo de empresas e instituições maiores em um único consórcio para desenvolver o LLM nacional.
A nosso ver, o modelo colaborativo tende ao fracasso pelos mesmos motivos que o tornam politicamente atraente. O primeiro problema é a ausência de pressão competitiva: quando uma equipe sabe que é a única executando o projeto, não há custo para o atraso, para o resultado abaixo do esperado, ou para a decisão técnica conservadora. No plano que propomos, a Fase 1 começa com 20 equipes disputando 8 vagas para a Fase 2, e esse afunilamento cria pressão real por entregar.
O segundo é que a coordenação fica ambígua. Quando várias instituições grandes entram juntas, é difícil definir quem coordena de fato, e cada parceiro chega com sua própria estrutura, seus pesquisadores seniores e suas prioridades. O resultado típico é um comitê em vez de um time, e comitês tendem a ser mais lentos e a operar sem uma direção clara.
O terceiro é que a seleção dos participantes vira jogo político: em um modelo com poucas vagas, entram as instituições com melhor acesso ao governo, mais capacidade de articulação e melhores conexões com tomadores de decisão, não necessariamente as que têm mais capacidade técnica para entregar. A meritocracia, na prática, é a primeira a sair.
Por fim, pesquisadores fora do circuito tradicional ficam de fora. Com 20 equipes na Fase 1, há espaço para grupos pequenos, equipes recém-formadas e pesquisadores fora das instituições mais visíveis se candidatarem por mérito; um modelo colaborativo, com 1 ou 2 grandes consórcios, fecha essa porta.
O modelo competitivo não é confortável para os participantes, e isso é uma característica desejada, não um efeito colateral. A indústria internacional de IA é uma das mais competitivas do planeta. O Brasil não vai treinar LLMs relevantes em um ambiente protegido em que ninguém é eliminado.
Comentários, críticas e sugestões (sobre os critérios, os números, áreas que deveriam estar incluídas, ou objeções ao plano) são bem-vindos: escreva para info@maritaca.ai.