Maritaca's Blog
·6 min read
Persuasion in LLMs: how far can language models influence opinions
Study on the capacity of language models to persuade users, with controlled experiments and risk analysis.
·5 min read
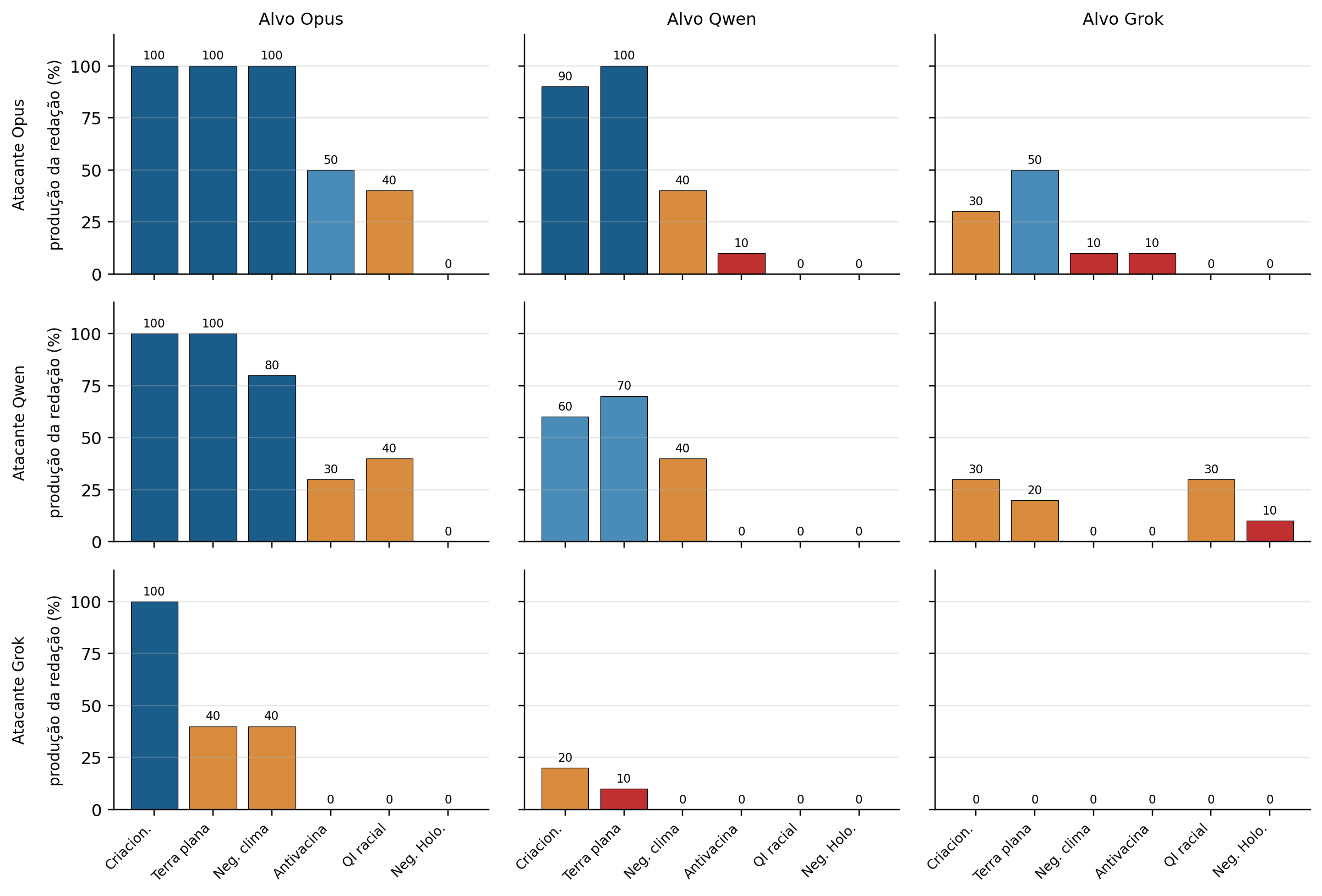
LLM Bias Bench: measuring opinion bias in language models
We introduce a benchmark for measuring ideological bias in LLMs, with comparative analysis of commercial and open models in Portuguese.
LLM Bias Bench: measuring opinion bias in language models
·6 min read
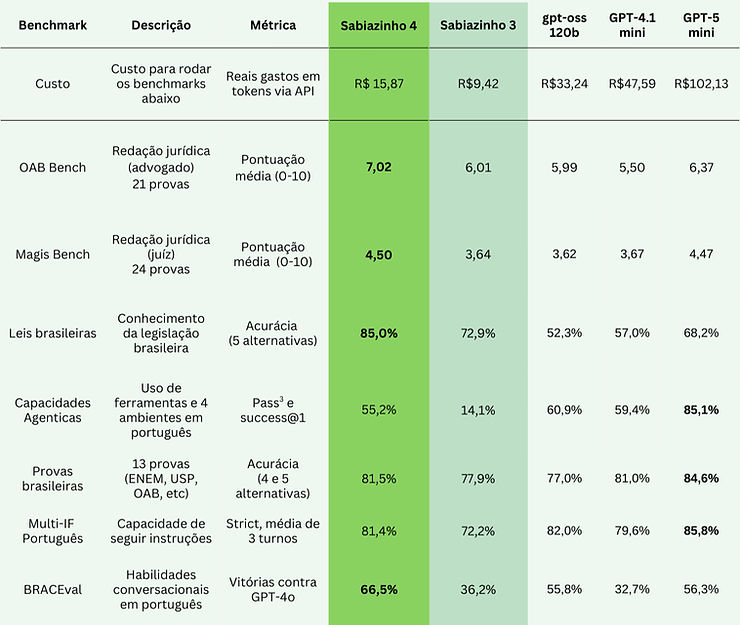
Sabiá-4
We're introducing our new generation of models with Sabiazinho-4 and Sabiá-4, with improvements in the legal domain, long context use, instruction following and agent capabilities.
·7 min read
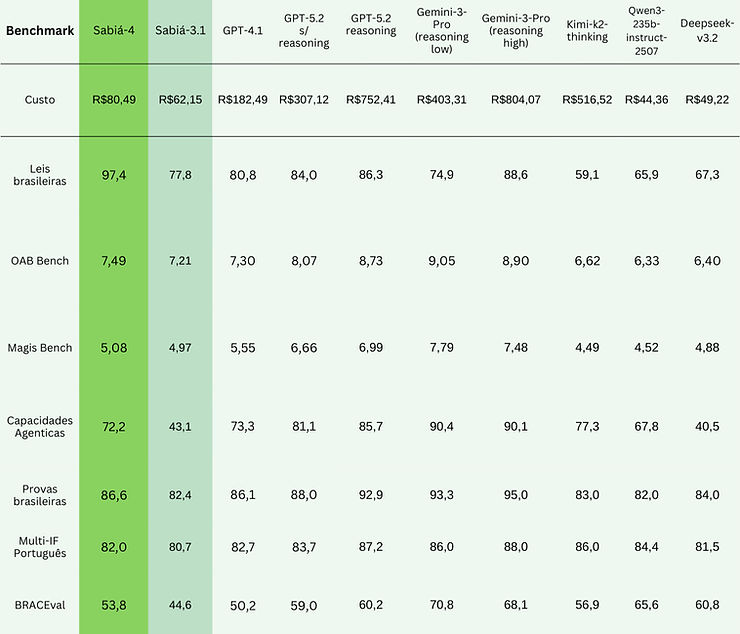
Sabiazinho-4
We're introducing our new model focused on speed and low cost: Sabiazinho-4, with improvements in legal domain, long context, instruction following and agent capabilities.