Sabiazinho-4
We're introducing our new model focused on speed and low cost: Sabiazinho-4, with improvements in legal domain, long context, instruction following and agent capabilities.
We’re launching in preview Sabiazinho-4, the first model in the next generation of the Sabiá family, designed with a focus on cost and latency. The model represents a significant advance over Sabiazinho-3, especially in areas where the previous generation had limitations.
| Benchmark | Description | Metric | Sabiazinho 4 | Sabiazinho 3 | gpt-oss 120b | GPT-4.1 mini | GPT-5 mini |
|---|---|---|---|---|---|---|---|
| Cost | Cost to run benchmarks below | BRL spent on tokens via API | R$15.87 | R$9.42 | R$33.24 | R$47.59 | R$102.13 |
| OAB Bench | Legal writing (lawyer), 21 exams | Avg. score (0-10) | 7.02 | 6.01 | 5.99 | 5.50 | 6.37 |
| Magis Bench | Legal writing (judge), 24 exams | Avg. score (0-10) | 4.50 | 3.64 | 3.62 | 3.67 | 4.47 |
| Brazilian Laws | Knowledge of Brazilian legislation | Accuracy (5 options) | 85.0% | 72.9% | 52.3% | 57.0% | 68.2% |
| Agentic capabilities | Tool use across 4 Portuguese envs | Pass³ and success@1 | 55.2% | 14.1% | 60.9% | 59.4% | 85.1% |
| Brazilian exams | 13 exams (ENEM, USP, OAB, etc) | Accuracy (4-5 options) | 81.5% | 77.9% | 77.0% | 81.0% | 84.6% |
| Multi-IF Portuguese | Instruction following | Strict, avg of 3 turns | 81.4% | 72.2% | 82.0% | 79.6% | 85.8% |
| BRACEval | Portuguese conversational skills | Wins vs GPT-4o | 66.5% | 36.2% | 55.8% | 32.7% | 56.3% |
Table 1: performance and cost comparison across analyzed models.
Pre-training improvements
Identified key limitations in demanding scenarios for Sabiazinho-3 and improved pre-training:
- Brazilian legal domain — laws, precedents, decisions, legal writing.
- Long context — up to 128K tokens.
- Brazilian knowledge — current events, institutions, national literature.
- Agent capabilities — stable function calling and tool orchestration.
Post-training improvements
Also brought improvements to post-training, addressing previous-model gaps:
- Instruction following — more consistent responses.
- Function calling — model now invokes available functions correctly.
- Web search — proper use of external tools when needed.
In the figures below, we illustrate behavior differences between Sabiazinho-3 and Sabiazinho-4 when answering a simple question that requires a web search. Sabiazinho-3 didn’t call web_search() correctly; Sabiazinho-4 makes the call as expected.

Figure 1: response from the old Sabiazinho-3 model. Note the model not calling the function it has access to: web_search().
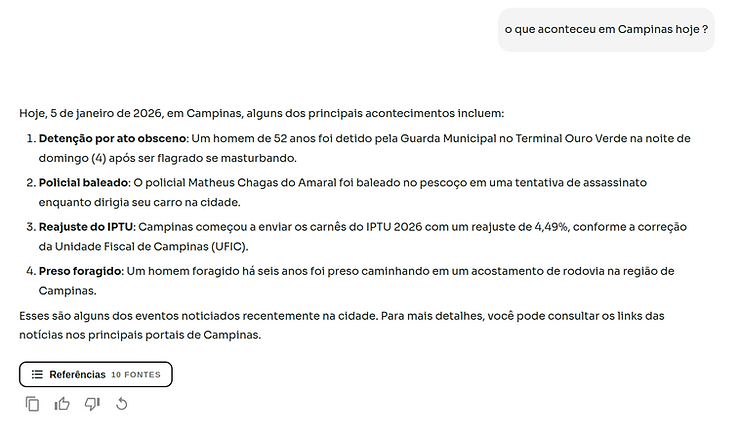
Figure 2: response from the new Sabiazinho-4 model. The new model makes the call correctly.
Total cost
When calculating real model cost, all factors matter: token price, latency, tokens per task, and benchmark-specific cost.
| Benchmark | sabiazinho-3 | sabiazinho-4 | gpt-oss-120b | gpt-4.1-mini | gpt-5-mini |
|---|---|---|---|---|---|
| OAB Bench | R$0.50 | R$0.81 | R$1.50 | R$1.20 | R$5.90 |
| Magis Bench | R$0.30 | R$0.46 | R$0.71 | R$0.89 | R$3.84 |
| Brazilian Laws | R$1.44 | R$1.97 | R$2.86 | R$2.74 | R$7.36 |
| Agentic capabilities | R$3.88 | R$7.70 | R$20.49 | R$33.75 | R$47.70 |
| Brazilian exams | R$0.62 | R$0.54 | R$1.62 | R$2.16 | R$8.51 |
| Multi-IF Portuguese | R$2.35 | R$3.71 | R$5.11 | R$6.18 | R$25.87 |
| BRACEval | R$0.33 | R$0.68 | R$0.96 | R$0.67 | R$2.95 |
| Total | R$9.42 | R$15.87 | R$33.24 | R$47.59 | R$102.13 |
Figure 12: costs in BRL to evaluate models on the published benchmarks.
Next steps
The launch of Sabiazinho-4 is an important step toward our next model generations. You can find more details on how to use the new model in our documentation: docs.maritaca.ai.