Sabiá-4
We're introducing our new generation of models with Sabiazinho-4 and Sabiá-4, with improvements in the legal domain, long context use, instruction following and agent capabilities.
We’re launching in preview Sabiá-4, our next-generation model in the Sabiá family, designed with a focus on cost and performance for complex tasks. The models represent a significant advance over the previous generation, especially in areas where the older version had limitations.
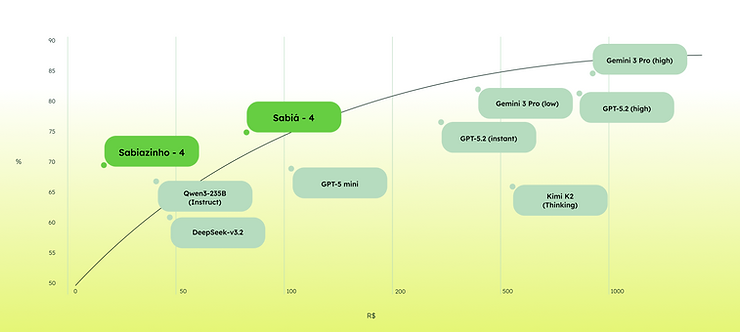
Figure 1: cost (X axis) vs quality (Y axis) of evaluated models.
Pre-training improvements
We identified key limitations in more demanding scenarios for the previous generation and improved our pre-training to cover these areas:
- Brazilian legal domain — laws, precedents, decisions and legal writing.
- Long context — up to 128K tokens, ideal for analyzing court cases and contracts.
- Brazilian knowledge — current events, institutions and national literature.
- Agent capabilities — stable function calling and tool orchestration.
Post-training improvements
We also brought improvements to post-training, especially to address gaps in the previous generation:
- Instruction following — more consistent, faithful responses to user requests.
- Function calling — correct execution in complex environments.
- Web search — appropriate use of external tools when available.
Benchmark evaluation
The models were evaluated on multiple benchmarks. The tables below show performance across price tiers.
| Benchmark | Sabiá-4 | Sabiá-3.1 | GPT-4.1 | GPT-5.2 no reasoning | GPT-5.2 reasoning | Gemini-3-Pro (reasoning low) | Gemini-3-Pro (reasoning high) | Kimi-k2- thinking | Qwen3- 235b- instruct-2507 | Deepseek- v3.2 |
|---|---|---|---|---|---|---|---|---|---|---|
| Cost | R$80.49 | R$62.15 | R$182.49 | R$307.12 | R$752.41 | R$403.31 | R$804.07 | R$516.52 | R$44.36 | R$49.22 |
| Brazilian Laws | 97.4 | 77.8 | 80.8 | 84.0 | 86.3 | 74.9 | 88.6 | 59.1 | 65.9 | 67.3 |
| OAB Bench | 7.49 | 7.21 | 7.30 | 8.07 | 8.73 | 9.05 | 8.90 | 6.62 | 6.33 | 6.40 |
| Magis Bench | 5.08 | 4.97 | 5.55 | 6.66 | 6.99 | 7.79 | 7.48 | 4.49 | 4.52 | 4.88 |
| Agentic capabilities | 72.2 | 43.1 | 73.3 | 81.1 | 85.7 | 90.4 | 90.1 | 77.3 | 67.8 | 40.5 |
| Brazilian exams | 86.6 | 82.4 | 86.1 | 88.0 | 92.9 | 93.3 | 95.0 | 83.0 | 82.0 | 84.0 |
| Multi-IF Portuguese | 82.0 | 80.7 | 82.7 | 83.7 | 87.2 | 86.0 | 88.0 | 86.0 | 84.4 | 81.5 |
| BRACEval | 53.8 | 44.6 | 50.2 | 59.0 | 60.2 | 70.8 | 68.1 | 56.9 | 65.6 | 60.8 |
Table 1: Sabiá-4 — quality and cost comparison across frontier models.
Below we highlight some of the main benchmarks.
OAB-Bench
OAB-Bench is a benchmark that evaluates language models on complex legal-writing tasks, based on the second phase of Brazil’s Bar exam (OAB). It includes 105 questions from recent editions of the exam, distributed across seven areas of law, with the same complete evaluation guidelines used by human assessors.
Magis-Bench
Magis-Bench evaluates LLMs on highly complex legal tasks, focusing on Brazilian public-service exams for substitute judge positions. It is built from real, recent exam materials, including a written exam and two practical exams (civil and criminal sentences).
Ticket-Bench
Ticket-Bench evaluates models’ ability to operate a soccer-ticket purchase platform — searching matches, picking seats and completing the purchase.
Pix-Bench
Pix-Bench evaluates models on everyday financial tasks like paying a bill or sending a Pix transfer. Acting as a banking assistant, the model must interpret the user request and execute the correct action.
MARCA (MAritaca Research Checklist evAluation)
MARCA evaluates models on finding information via web navigation, focusing on questions that require breadth-first search across multiple sources. Each question comes with a checklist used to assess answer completeness and correctness.
CLIMB (CheckList-based Inference for Multihop with Browsing)
CLIMB tests models on multi-hop chained search until reaching a final answer — questions requiring browsing across linked pages.
Brazilian Laws
This benchmark evaluates models on Brazilian federal legislation (50,000+ acts including laws, decrees, provisional measures). Multiple-choice in two variations: identify the law a passage belongs to, or identify the exact reference.
Multi-IF
Multi-IF evaluates whether models can follow instructions that accumulate across a multi-turn conversation, with constraints added each turn.
BRACeval (Brazilian Chat Evaluation)
BRACEval evaluates chatbots on open-ended, complex multi-turn instructions emphasizing Brazilian context — 150 questions across 13 categories.
Total cost
When calculating the real cost of a language model, all factors matter: token price, latency, tokens per task, and benchmark-specific cost.
| Benchmark | Sabiá-4 | Sabiá-3.1 | GPT-4.1 | GPT-5.2 no reasoning | GPT-5.2 reasoning | Gemini-3-Pro (reasoning low) | Gemini-3-Pro (reasoning high) | Kimi-k2- thinking | Qwen3- 235b- instruct | Deepseek- v3.2 |
|---|---|---|---|---|---|---|---|---|---|---|
| OAB Bench | R$3.06 | R$2.17 | R$6.26 | R$9.02 | R$22.03 | R$12.11 | R$26.15 | R$12.68 | R$1.43 | R$0.75 |
| Magis Bench | R$2.44 | R$1.74 | R$4.88 | R$9.33 | R$23.91 | R$14.39 | R$24.89 | R$8.07 | R$0.69 | R$0.49 |
| Brazilian Laws | R$7.18 | R$7.89 | R$13.73 | R$11.97 | R$37.38 | R$31.68 | R$86.33 | R$33.17 | R$1.99 | R$2.19 |
| Agentic capabilities | R$35.97 | R$25.49 | R$102.15 | R$181.09 | R$467.29 | R$178.90 | R$224.55 | R$304.58 | R$27.47 | R$38.81 |
| Brazilian exams | R$6.36 | R$4.38 | R$7.48 | R$4.21 | R$30.77 | R$36.32 | R$101.22 | R$41.37 | R$3.07 | R$1.65 |
| Multi-IF Portuguese | R$16.08 | R$13.80 | R$28.73 | R$58.80 | R$97.76 | R$79.40 | R$206.23 | R$70.62 | R$5.43 | R$3.55 |
| BRACEval | R$2.38 | R$1.48 | R$3.74 | R$7.50 | R$13.51 | R$11.27 | R$28.50 | R$10.64 | R$0.90 | R$0.50 |
| Total | R$80.49 | R$62.15 | R$182.49 | R$307.12 | R$752.41 | R$403.31 | R$804.07 | R$516.52 | R$44.36 | R$49.22 |
Figure 11: Sabiá-4 — costs in BRL to evaluate models on the published benchmarks.
Next steps
The launch of generation 4 (Sabiazinho-4 and Sabiá-4) is an important step toward our next model generations. You can find more details on how to use the new model in our documentation: docs.maritaca.ai.