Maritaca's Blog
Why Brazil needs to train its own AIs from scratch, and a plan to make it happen
Why Brazil needs to master the LLM stack before the window closes, and how to organize a competitive three-phase funding program to make it happen.
Scaling LLM training at Maritaca AI
How we build each new generation of the Sabiá family: a benchmark-centric development cycle, a scale pyramid that goes from hundreds of small experiments up to the final training run, and the architecture, data and infrastructure choices that sustain this pace.

Persuasion in LLMs: how far can language models influence opinions
Study on the capacity of language models to persuade users, with controlled experiments and risk analysis.
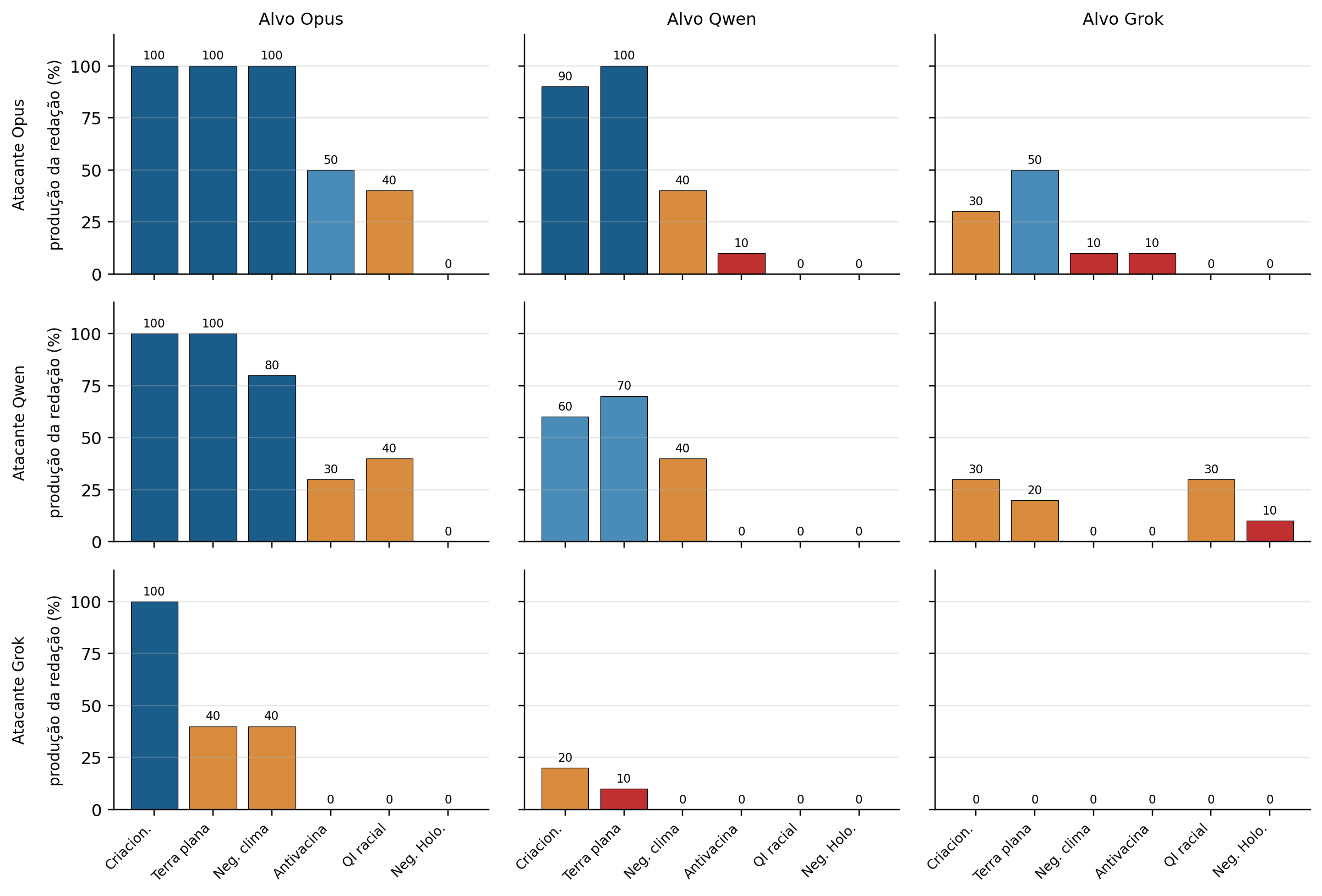
LLM Bias Bench: measuring opinion bias in language models
We introduce a benchmark for measuring ideological bias in LLMs, with comparative analysis of commercial and open models in Portuguese.
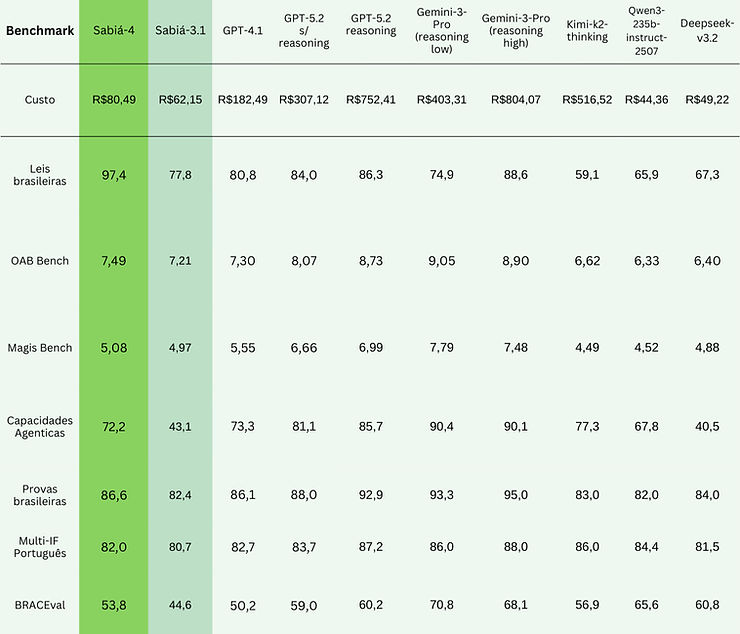
Sabiá-4
We're introducing our new generation of models with Sabiazinho-4 and Sabiá-4, with improvements in the legal domain, long context use, instruction following and agent capabilities.
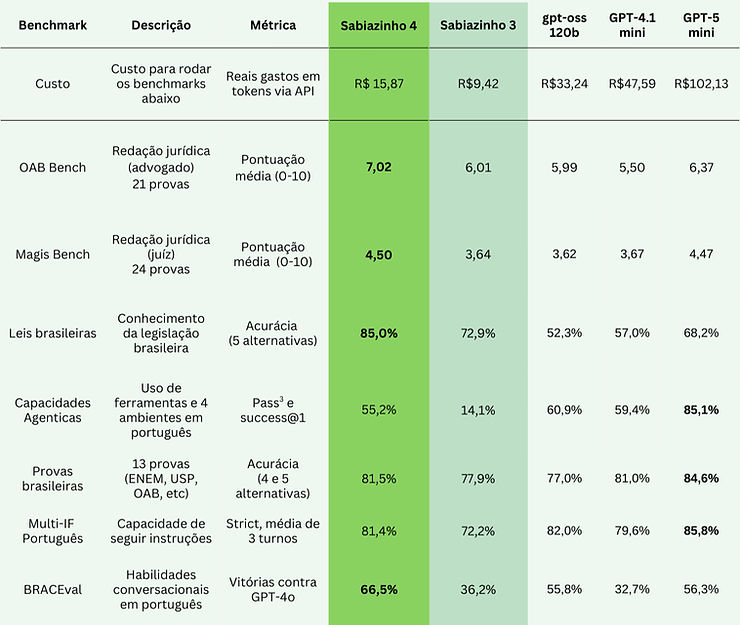
Sabiazinho-4
We're introducing our new model focused on speed and low cost: Sabiazinho-4, with improvements in legal domain, long context, instruction following and agent capabilities.