Sabiazinho-4
Estamos introduzindo nosso novo modelo focado em velocidade e baixo custo: Sabiazinho-4, com melhorias no domínio jurídico, uso de contexto longo, seguir instruções e capacidades de agente.
Estamos lançando em versão preview o Sabiazinho-4, o primeiro modelo da próxima geração da família Sabiá, projetado com foco em custo e latência. O modelo representa um avanço significativo em relação ao Sabiazinho-3, especialmente em pontos onde a geração antiga apresentava limitações.
| Benchmark | Descrição | Métrica | Sabiazinho 4 | Sabiazinho 3 | gpt-oss 120b | GPT-4.1 mini | GPT-5 mini |
|---|---|---|---|---|---|---|---|
| Custo | Custo para rodar os benchmarks abaixo | Reais gastos em tokens via API | R$15,87 | R$9,42 | R$33,24 | R$47,59 | R$102,13 |
| OAB Bench | Redação jurídica (advogado), 21 provas | Pontuação média (0-10) | 7,02 | 6,01 | 5,99 | 5,50 | 6,37 |
| Magis Bench | Redação jurídica (juíz), 24 provas | Pontuação média (0-10) | 4,50 | 3,64 | 3,62 | 3,67 | 4,47 |
| Leis brasileiras | Conhecimento da legislação brasileira | Acurácia (5 alternativas) | 85,0% | 72,9% | 52,3% | 57,0% | 68,2% |
| Capacidades agênticas | Uso de ferramentas e 4 ambientes em português | Pass³ e success@1 | 55,2% | 14,1% | 60,9% | 59,4% | 85,1% |
| Provas brasileiras | 13 provas (ENEM, USP, OAB, etc) | Acurácia (4 e 5 alternativas) | 81,5% | 77,9% | 77,0% | 81,0% | 84,6% |
| Multi-IF Português | Capacidade de seguir instruções | Strict, média de 3 turnos | 81,4% | 72,2% | 82,0% | 79,6% | 85,8% |
| BRACEval | Habilidades conversacionais em português | Vitórias contra GPT-4o | 66,5% | 36,2% | 55,8% | 32,7% | 56,3% |
Tabela 1: comparação de desempenho e custo entre os modelos analisados.
Melhorias no pré-treino
Identificamos algumas limitações importantes em cenários mais exigentes para o Sabiazinho-3 e melhoramos nosso pré‑treino para cobrir esses pontos:
- Domínio jurídico brasileiro — leis, súmulas, decisões e redação jurídica.
- Contexto longo — até 128 mil tokens.
- Conhecimento sobre o Brasil — atualidades, instituições e literatura nacional.
- Capacidades de agente — function calling estável e orquestração de ferramentas.
Melhorias no pós-treino
Também trouxemos melhorias no pós‑treino do Sabiazinho-4, especialmente para cobrir limitações do modelo antigo:
- Seguimento de instruções — respostas mais consistentes.
- Chamada de funções — agora o modelo invoca corretamente as funções disponíveis.
- Busca na web — uso adequado de ferramentas externas quando necessário.
Nas figuras a seguir, ilustramos a diferença de comportamento entre o Sabiazinho-3 e o Sabiazinho-4 ao responder a uma pergunta simples que exige uma busca na internet. O Sabiazinho-3 não chamava a função web_search() corretamente; o Sabiazinho-4 faz a chamada como esperado.

Figura 1: resposta dada pelo modelo antigo — Sabiazinho-3. Destaque para o modelo não chamando a função à qual tem acesso: web_search().
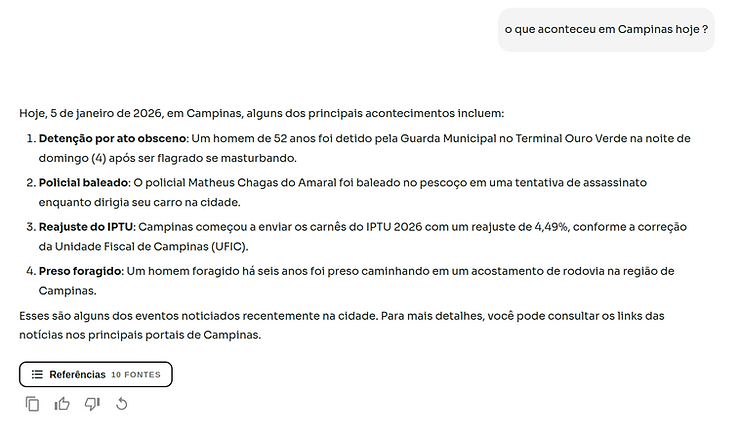
Figura 2: resposta dada pelo modelo novo — Sabiazinho-4. É possível ver que o novo modelo fez a chamada corretamente.
Avaliação em benchmarks
O Sabiazinho-4 foi avaliado em diversos benchmarks de avaliação:
OAB-Bench
OAB-Bench é um benchmark criado para avaliar a capacidade de modelos de linguagem em tarefas complexas de escrita jurídica, usando como base a segunda fase do Exame da OAB. O benchmark reúne 105 questões distribuídas em sete áreas do direito.
Magis-Bench
Magis-Bench é um benchmark voltado à avaliação de modelos de linguagem em tarefas jurídicas de alta complexidade, com foco em concursos públicos para juiz substituto no Brasil. Provas reais e recentes incluem prova discursiva e duas provas práticas (sentença cível e criminal).
Ticket-Bench
Ticket-Bench avalia a capacidade dos modelos de operar uma plataforma de compra de ingressos de jogos de futebol — buscar partidas, escolher assentos e finalizar a compra.
Pix-Bench
Pix-Bench avalia a capacidade de modelos auxiliarem em tarefas financeiras cotidianas, como pagar uma conta ou fazer um Pix. O modelo assume o papel de assistente de uma plataforma bancária e precisa interpretar o pedido do usuário e executar a ação correta.
MARCA (MAritaca Research Checklist evAluation)
MARCA avalia as capacidades dos modelos de encontrar informação através de navegação na web, focando principalmente em perguntas que demandam busca em largura. Cada pergunta é acompanhada de um checklist usado para avaliar completude e corretude da resposta.
CLIMB (CheckList-based Inference for Multihop with Browsing)
CLIMB testa a habilidade dos modelos em realizar buscas em cadeia (multi-hop) até alcançar uma resposta final, com perguntas complexas que exigem navegação encadeada entre páginas.
Leis Brasileiras
Este benchmark avalia o conhecimento dos modelos sobre a legislação federal brasileira (mais de 50 mil atos normativos). As questões são de múltipla escolha em duas variações: identificar a qual lei pertence um trecho, ou identificar a referência exata.
Multi-IF
O Multi-IF avalia se modelos são capazes de seguir instruções que se acumulam ao longo de uma conversa multi-turno, com restrições adicionadas a cada turno.
BRACeval (Brazilian Chat Evaluation)
BRACEval é um benchmark de perguntas abertas voltado à avaliação de chatbots em cenários complexos com ênfase no conhecimento sobre o Brasil. 150 perguntas multi-turno distribuídas em 13 categorias contextualizadas ao Brasil.
Custo total
Ao calcular o custo real de um modelo de linguagem, é importante considerar todos os fatores: preço por token de entrada e saída, latência, número de tokens necessários por tarefa e custo por benchmark.
| Benchmark | sabiazinho-3 | sabiazinho-4 | gpt-oss-120b | gpt-4.1-mini | gpt-5-mini |
|---|---|---|---|---|---|
| OAB Bench | R$0,50 | R$0,81 | R$1,50 | R$1,20 | R$5,90 |
| Magis Bench | R$0,30 | R$0,46 | R$0,71 | R$0,89 | R$3,84 |
| Leis brasileiras | R$1,44 | R$1,97 | R$2,86 | R$2,74 | R$7,36 |
| Capacidades agênticas | R$3,88 | R$7,70 | R$20,49 | R$33,75 | R$47,70 |
| Provas brasileiras | R$0,62 | R$0,54 | R$1,62 | R$2,16 | R$8,51 |
| Multi-IF Português | R$2,35 | R$3,71 | R$5,11 | R$6,18 | R$25,87 |
| BRACEval | R$0,33 | R$0,68 | R$0,96 | R$0,67 | R$2,95 |
| Total | R$9,42 | R$15,87 | R$33,24 | R$47,59 | R$102,13 |
Figura 12: custos em reais para avaliar os modelos nos benchmarks divulgados.
Próximos passos
O lançamento do Sabiazinho-4 é um passo importante para o desenvolvimento de nossas próximas gerações de modelos. Você pode encontrar mais detalhes sobre como usar o novo modelo em nossa documentação: docs.maritaca.ai.