Why Brazil needs to train its own AIs from scratch, and a plan to make it happen
Why Brazil needs to master the LLM stack before the window closes, and how to organize a competitive three-phase funding program to make it happen.
by Rodrigo Nogueira
A bit of background
I’m Rodrigo Nogueira, CEO and founder of Maritaca AI, a company specialized in training LLMs that are relevant for Brazil. I hold a PhD in Computer Science from New York University and I’m one of the most cited researchers in computer science in Brazil, according to Google Scholar. That track record comes from open-source work like BERTimbau, pioneering research on the use of deep learning models such as BERT (today considered a Small Language Model) for information retrieval, and more recently from training the Sabiá family of models (Sabiá-1, Sabiá-2, Sabiá-3, Sabiá-4) and from several benchmarks we have published over the years. If you’d like to know more about our work, see Maritaca’s research page and the post Scaling LLM training at Maritaca AI, where I explain in detail how we develop AI models in-house.
Recent advances in language models, combined with conversations with the academic community and with political and business leadership in Brazil, motivated me to write this document. Despite being long, I try to ground it in the perspective of someone on the front lines, someone who will be among the first to feel what Anthropic CEO Dario Amodei called the imminent bloodbath in the labor market, and in the inaction of Brazil’s economic, political and intellectual leadership in the face of what is coming.
The impact AI is bringing to the world
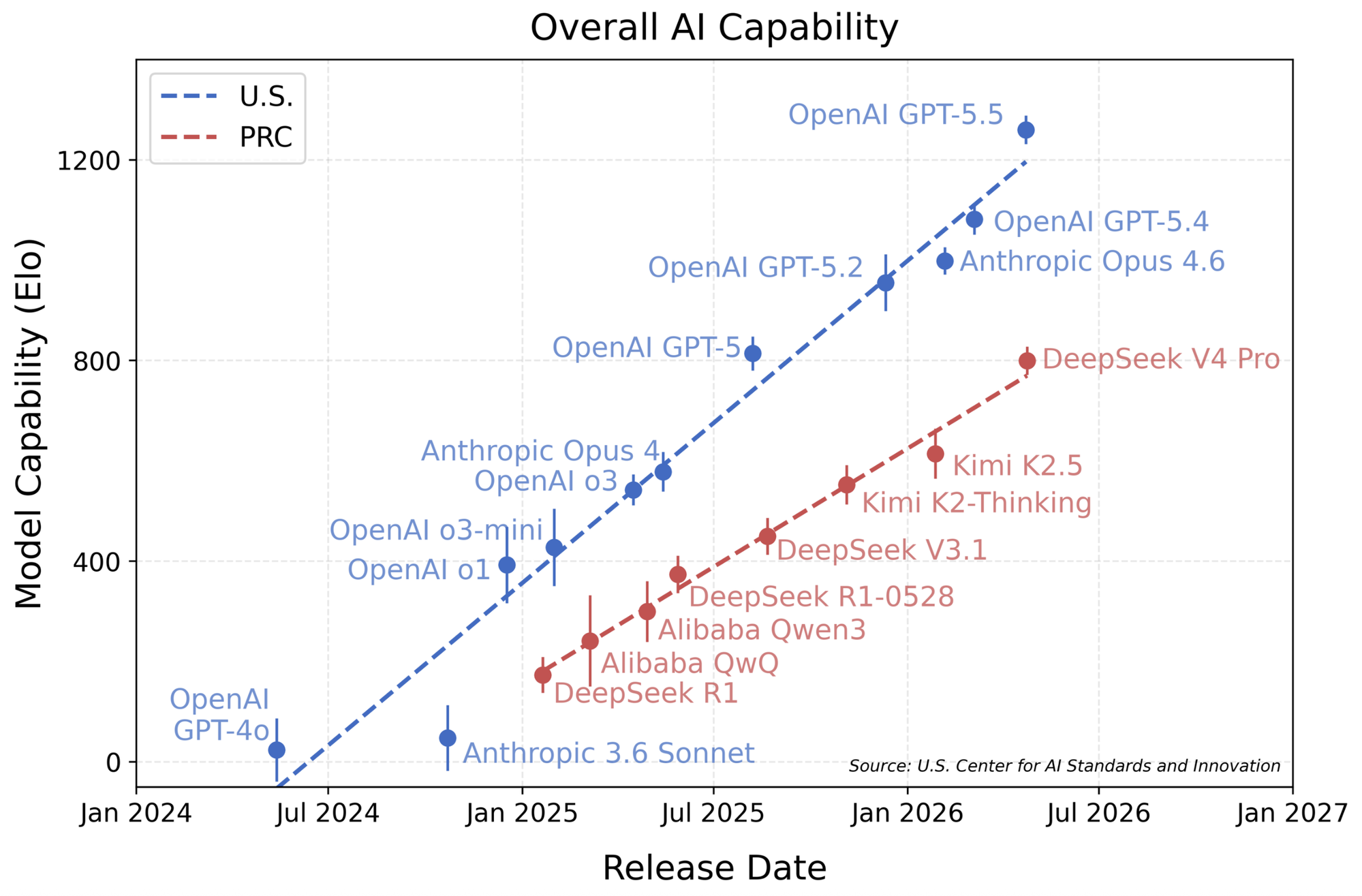
The capability gains of frontier models in the last two years have been extraordinary, and the objective measurements give the best sense of the scale.
According to measurements from METR.org, today’s best models, like Claude Mythos (still only available to a handful of companies, more on that later), can autonomously complete programming tasks that would take an experienced human programmer more than 10 hours.
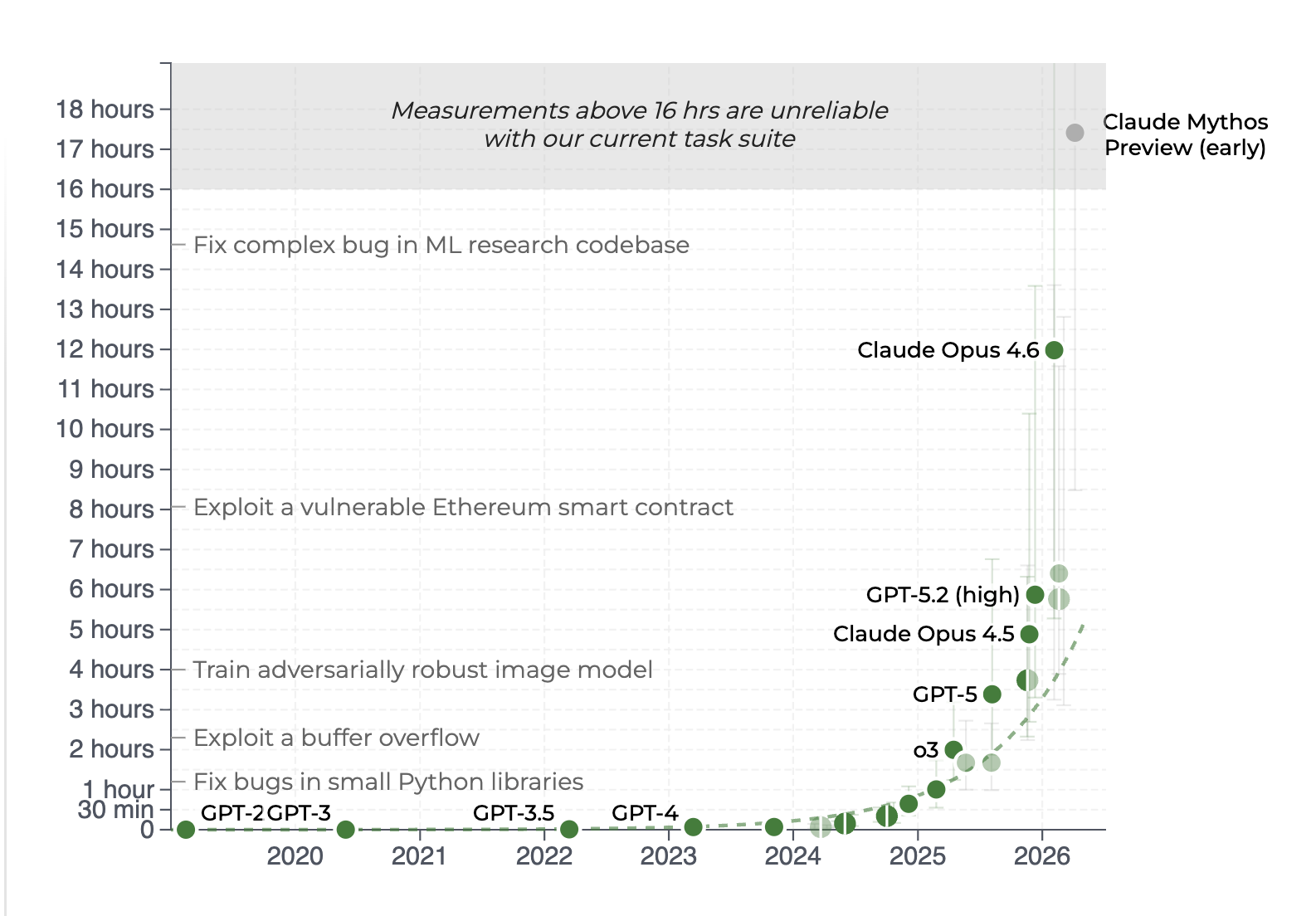
In another study, the UK AI Security Institute shows that the length of cybersecurity tasks frontier models can complete has been doubling every few months, and the rate has only accelerated: recent models exceeded the previous trend reported by the study itself.
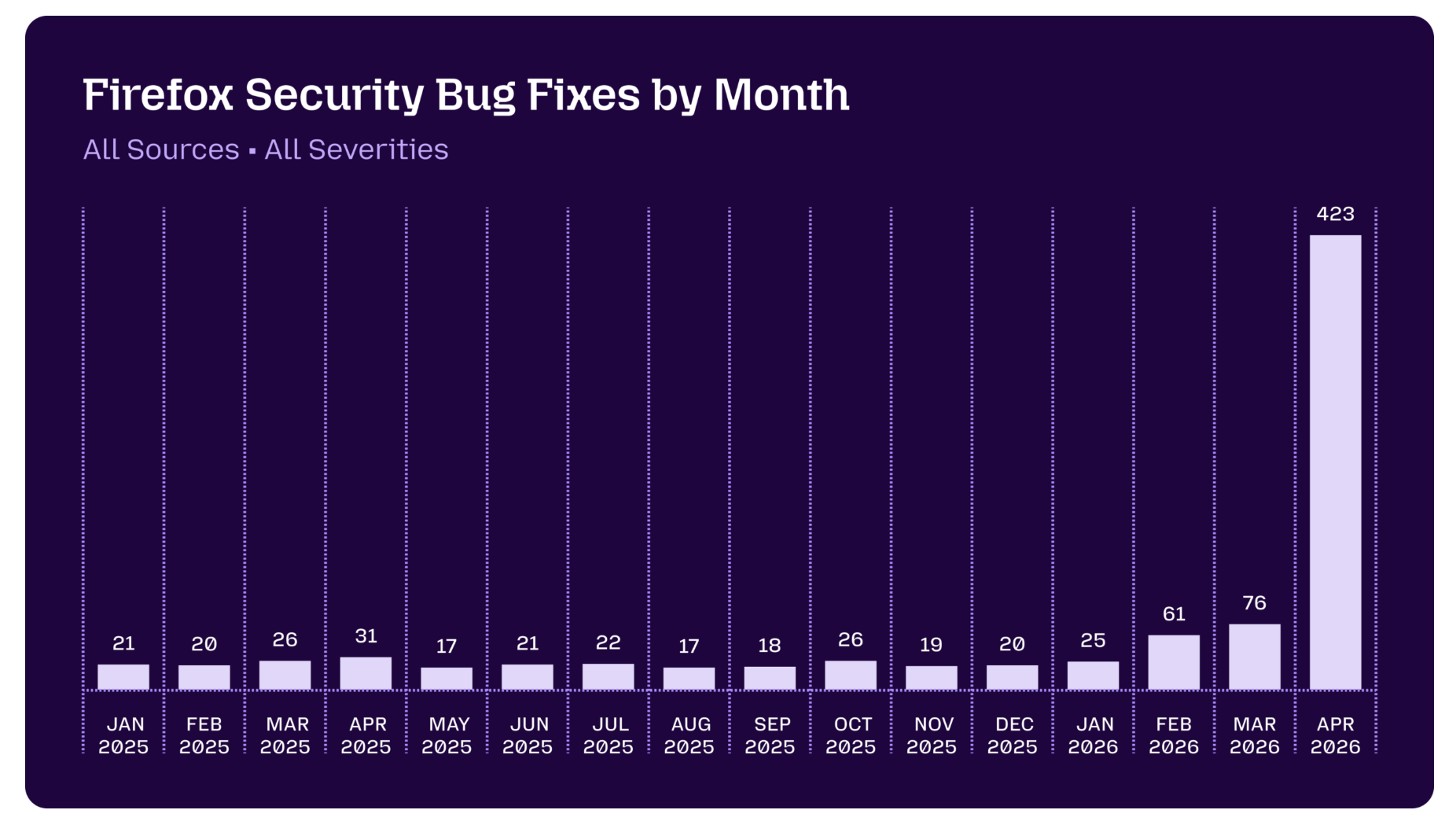
And these productivity gains don’t show up only in benchmarks. They show up in real applications. Mozilla, for example, reported that, thanks to Mythos, the number of vulnerabilities fixed in Firefox jumped from a baseline of 20–30 per month to 423 in April 2026 alone.
And it’s not just code. In March 2026, GPT-5.4 Pro became the first AI to solve a problem from the Erdős list that had been open since 2019, with independent verification by Epoch AI. In April, the same model solved in 80 minutes, from a single prompt, a problem that had resisted the mathematical community for 60 years. Fields medalist Terence Tao described the contribution as “a meaningful contribution to the anatomy of integers that goes well beyond the solution of this particular Erdős problem.” Since Christmas 2025, 15 open problems have been solved in mathematics; in 11 of them, AI played a direct role. AIs have stopped being a mere auxiliary tool and started contributing to frontier scientific production.
Perhaps the most direct economic signal comes from GDPval, OpenAI’s benchmark that measures AI performance on real tasks drawn from the day-to-day work of experienced professionals across 44 occupations (lawyers, engineers, doctors, accountants, programmers, designers, nurses etc.) spanning 9 sectors that account for roughly US$ 3 trillion in annual compensation. Unlike academic-style exams, each GDPval item is a real deliverable (document, spreadsheet, slide, diagram), blindly graded by professionals with an average of 14 years of experience. Frontier models are already near the ceiling: GPT-5.5 reaches 84.9% and Claude Opus 4.7 is around 80%. At these levels, AI ties or outperforms the human professional on a substantial share of tasks. The effect is immediate on any occupation that spends most of the day in front of a computer, the so-called knowledge workers: lawyers, accountants, financial analysts, journalists, managers, software engineers, designers.
At Maritaca itself, 100% of our code is now written by AIs, and the development loop (experiment orchestration, hypothesis generation) is also partly conducted with AI assistance.
If only a handful of companies chosen by Anthropic can benefit from these capabilities, what is left for us as a country? Outsourcing artificial intelligence, which will generate a large fraction of nations’ intellectual capital in the coming years, looks like an extremely high-risk operation given the power it confers on those who hold the technology.
Because this is such a capital-intensive operation, it’s likely that few companies in the world will manage to train frontier LLMs. Brazil, with more than 200 million inhabitants, ranking somewhere between the seventh and tenth largest economy in the world (depending on the ranking), should position itself as an alternative to Chinese and American AIs. When Chinese companies stop publishing open-weights models (more on this below), what will we do? Will we depend on these few frontier companies to supply intelligence to us?
Will we let foreign AIs:
- write parts of our judicial decisions (CNJ Resolution nº 615/2025 authorizes LLMs to draft judicial documents, and the São Paulo Court already has its “Ementa Generator” in production, backed by Azure OpenAI);
- analyze financial statements and audit public spending (Brazil’s Federal Audit Court has already deployed ChatTCU, built on top of foreign LLMs);
- decide who gets credit lines;
- design political campaigns and electoral strategies;
- support economic and production decisions in government bodies and companies;
- shape public policy in health, security and education;
- triage patients in public hospitals and answer citizens;
- moderate what can or can’t circulate on Brazilian social media.
At the first political disagreement, a dictator or authoritarian president could threaten to cut off the supply of these AIs to Brazil. And if the world becomes bipolar again, we’ll have to turn to the other side, which, knowing we have no alternative, will extract the maximum possible from us in negotiations. If we have alternative versions here, even if they’re not at the frontier, we’ll have far more cards to play.
Open-weights vs commercial models
You might be wondering: but why should I worry about this if we have open-weights models and I can run them or finetune them locally?
Today this race has only two horses out in front: OpenAI and Anthropic, with a third just behind (Google), and a crowd of companies, including Chinese open-weights ones, trying to catch up. But the gap is not closing. Let’s look at the data.
The quality gap
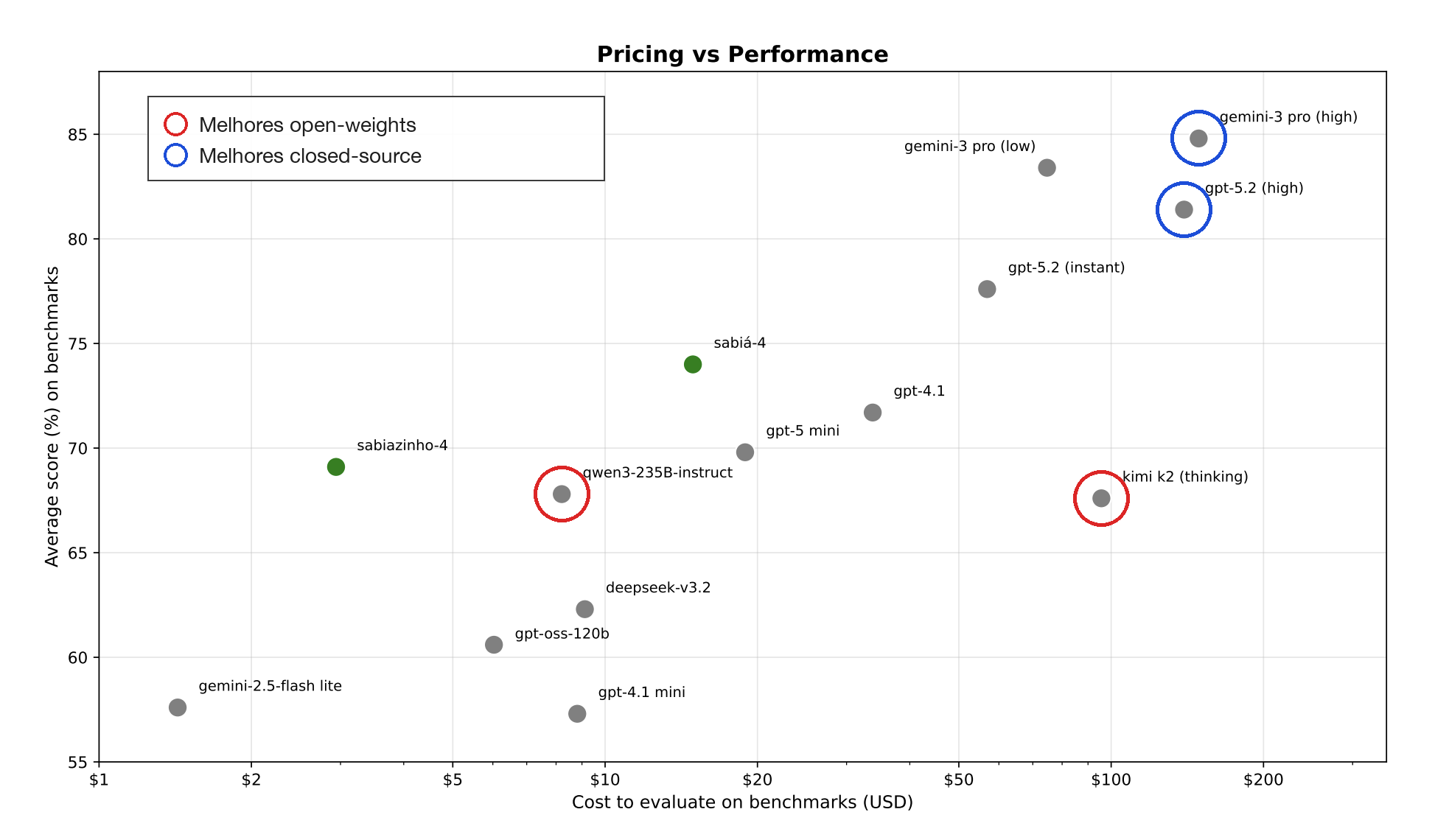
At Maritaca we evaluate many language models, commercial and open-weights, across a battery of benchmarks that cover capabilities relevant to our clients: analysis of multiple documents, web navigation, knowledge of geography, history, economics, medicine, drafting of legal documents, among others. The figure below, taken from the Sabiá-4 technical report, shows the gap between commercial closed-source models (GPT and Gemini families) and the best frontier open-weights (Kimi K2, Qwen3-235B): despite the progress, open-weights models clearly lag behind.
And our study isn’t the only one to reach this conclusion. The Center for AI Standards and Innovation (CAISI) showed that the gap between open-weights and commercial models is not narrowing: it’s widening.
We also observe something important: the real performance of open-weights models, measured in external benchmarks, tends to be much lower than the performance claimed by the companies themselves. The chart below makes this explicit. The left panel, based on benchmarks reported by DeepSeek’s own official report, places the model on par with frontier closed-source systems like Claude Opus 4.6. The right panel, from an external CAISI study run on internal benchmarks (not previously known to the companies), shows that DeepSeek V4-Pro-Max, today the best open-weights frontier model, exhibits a clear gap relative to Claude Opus 4.6 and GPT-5.4.
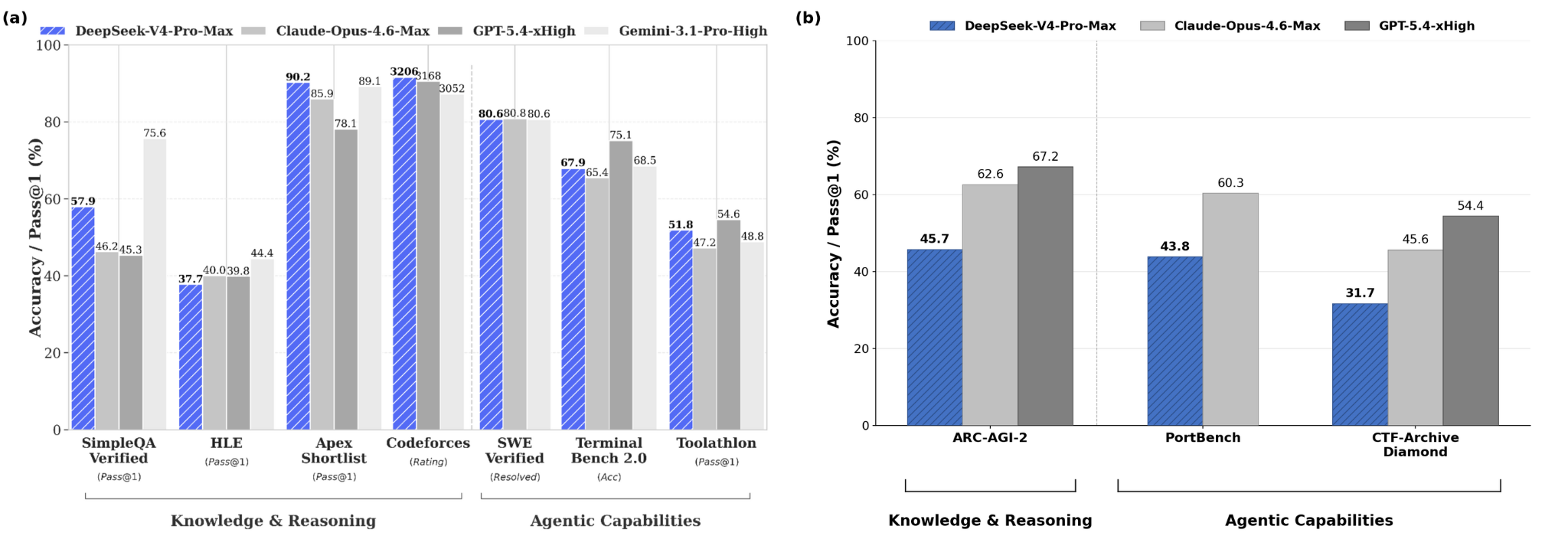
So if we rely on open-weights models to build our industry, we’re starting from inferior intelligence, and consequently delivering inferior products.
Fewer and fewer frontier candidates
There is an even bigger problem: what we have observed over the last few years is that fewer serious open-weights candidates are showing up at the frontier. Two or three years ago we had a reasonable constellation of competitors: Mistral, Llama, Qwen, Yi, DeepSeek. Mistral, Llama, Qwen and Yi no longer publish their best models openly. Qwen3.6 open-weights, for instance, was released only in the 35B version, which we estimate to be comparable to GPT-5-nano, the smallest and weakest of the GPT-5 family.
Models like GLM, Kimi and Minimax fall well short in quality across the benchmarks we run, despite announcements claiming they compete with GPT-5.5. Don’t get me wrong: these models are not bad, and the companies are not cheating. It’s simply that generalization is hard. Generalization, in machine learning, refers to a model’s ability to maintain good performance under conditions (tasks) different from those it was originally trained on. Models that pass generalization tests are the ones preferentially adopted by users and companies. The exception today is DeepSeek V4, which, according to our tests, holds up reasonably better than other open-weights, although it is still far from the three frontier models.
Who dominates real usage
To estimate which models are actually being used in the wild, we can look at OpenRouter. For those unfamiliar with it: OpenRouter is a routing platform that gives unified access, through a single API, to hundreds of models from dozens of providers (OpenAI, Anthropic, Google, DeepSeek, Qwen, Mistral, xAI, and so on). Because it concentrates the traffic of thousands of developers and products, OpenRouter’s public ranking works as a reasonably reliable thermometer of which model is actually being consumed today.
And what does that thermometer show? Those dominating traffic are OpenAI, Anthropic and Gemini. The top four are closed-source and, even costing several times more per token than their open-weights competitors, they dominate usage with more than 65% market share. It’s worth noting that OpenRouter is an estimate focused on the Western developer market and may not reflect well enterprise usage, which typically goes through direct contracts with the provider. But even with those caveats, the signal is strong.
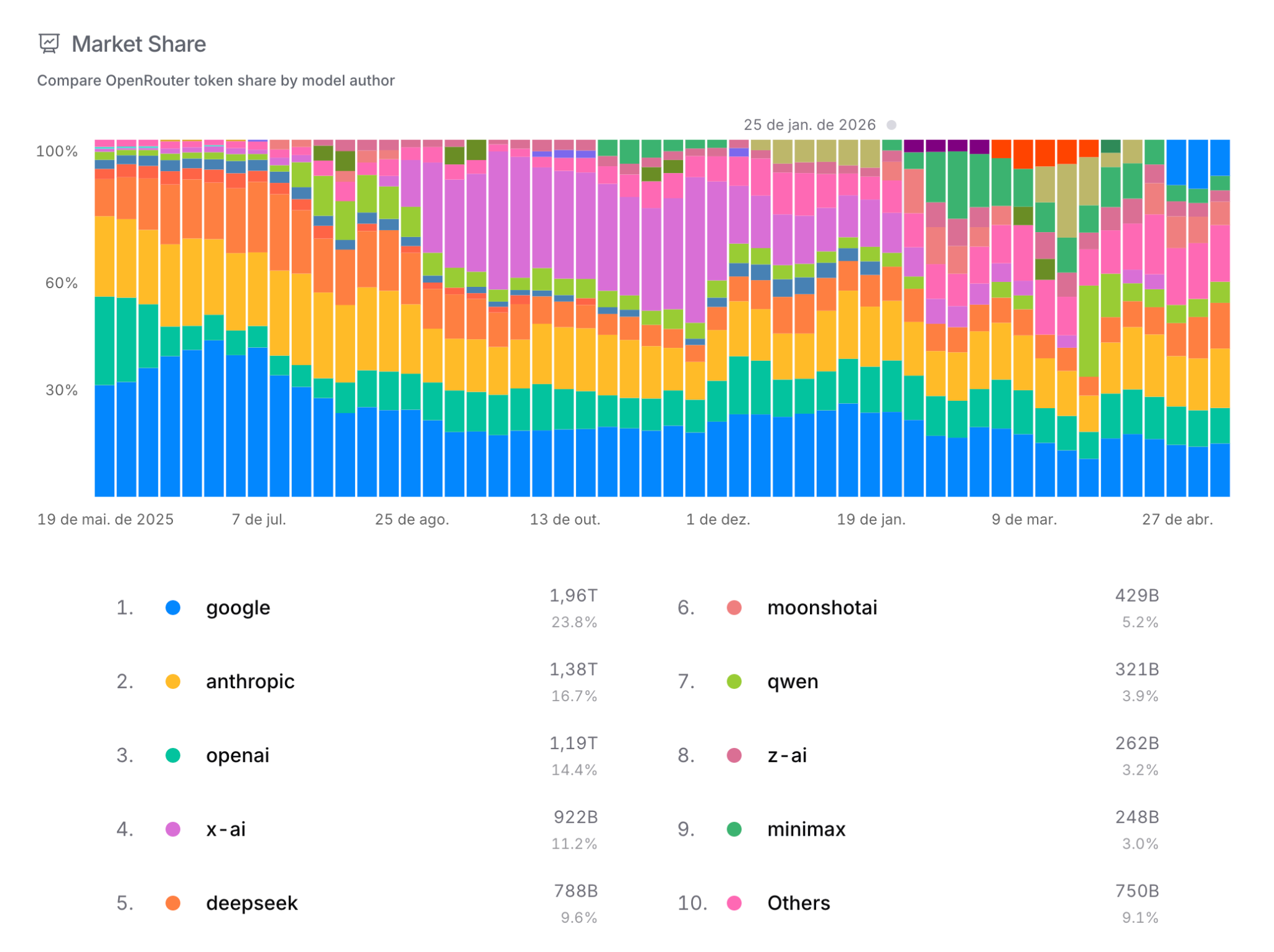
The message: if you really want to free yourself from dependency on these three companies, you’ll need to finetune an open-weights model yourself. This task is not easy, and it’s what we specialize in at Maritaca. Let’s discuss next what it involves.
Training from scratch vs finetuning
Before continuing, a definition: throughout this document I use finetuning in a broad sense, meaning any procedure that modifies the weights of an existing model, whether by continued pre-training, SFT (supervised fine-tuning) or reinforcement learning. In some contexts the term is used more narrowly (just SFT), but here it covers the entire post-training pipeline applied on top of an open-weights checkpoint.
Conceptually, finetuning and training from scratch differ in scale and diversity, not in pipeline.
For pre-training, you need to collect diverse data from the domain you want to teach the model. Then you need SFT (supervised fine-tuning) on dozens or hundreds of subtasks so the model becomes generalizable, that is, behaves well in cases slightly different from those it saw during training. That diversity is what brings generalization. Finally, any AI lab aiming for the frontier needs a wide variety of reinforcement-learning environments. Again: diversity is the key.
Finetuning an open-weights model is essentially reproducing this pipeline on a smaller scale.
| Stage | Training from scratch (frontier) | Open-weights finetuning | ||
|---|---|---|---|---|
| Tokens | Compute cost | Tokens | Compute cost | |
| Pre-training | 10–30 trillion | US$ 100M to 1B+ | 100B to 1T | US$ 1M to 10M |
| SFT | 10B to 100B | US$ 1M to 10M | 1B to 10B | US$ 50K to 500K |
| Reinforcement learning | 100B to 1T (rollouts) | US$ 10M to 100M+ | 10B to 100B (rollouts) | US$ 500K to 10M+ |
Table 1: orders of magnitude for each step of the pipeline. Numbers vary with architecture, available infrastructure, parallelization efficiency, and the number of iterations needed to get training right. Estimates based on spot and on-demand neocloud pricing in May 2026.
The message is: even with open-weights LLMs available, they are of inferior quality, and competitive finetuning of them requires substantial expertise.
And, as the table above shows, the cost of training a model from scratch is in the range of hundreds of millions to billions of dollars. An important note: many people believe that, because of the DeepSeek paper claiming you can train an LLM for US$ 5M, they could do the same. In our post on training scale, I show that we need to train smaller models several hundred (sometimes thousands of) times to master every stage of the technique. Adding it all up, and considering you’re unlikely to get the largest model right on the first try, the cost goes up to the order of hundreds of millions or billions of dollars.
It’s also worth asking: who has the financial firepower to spend that kind of money in the name of science? Certainly not the hedge fund backing DeepSeek. They will probably have to draw up a commercial plan soon to make the operation profitable, before it gets cut. It’s not a question of whether frontier open-weights models will dry up, it’s a question of when.
I hope by this point I’ve convinced you of the importance of having our own AI and mastering this stack. If you still don’t think it matters, please at least look at the action plan below. You’ll see that the proposed budget is not even a fraction of the budget currently allocated to FINEP grants for LLM applications, which usually don’t result in profitable commercial products.
Action plan
The plan below is inspired by South Korea’s Sovereign AI Foundation Model Project, run by MSIT (Ministry of Science and ICT) with a KRW 213.6 billion budget (~US$ 160M / ~R$ 800M) and a funnel structure: 15 initial applications, 5 consortia selected in August 2025 (LG AI Research, SK Telecom, Upstage, Naver Cloud, NC AI), 3 advancing after the first evaluation in January 2026 (LG, SKT and Upstage), with further evaluations every 6 months for up to 3 years. Teams receive mostly GPU leasing, with additional funding for data acquisition and processing and for hiring top-tier researchers.
The goal is to fund multiple teams to attempt training LLMs from scratch and progressively reduce the number of teams in subsequent phases, concentrating more compute on those that advance.
The central idea of the plan is simple: fund multiple labs, including Maritaca, to gain access to the compute required to train models from scratch. After 1.5 years, the goal is not to deliver a model that rivals GPT-5.5, but to light the spark: build the technical workforce, the infrastructure and the pre-training know-how that sustain a Brazilian AI industry. Without this initial push, it’s unlikely this will happen by private-sector initiative. The path of least resistance, from the standpoint of fast returns, is to use existing open-weights models or build what have come to be called GPT wrappers: products that are essentially an interface or a prompt-flow on top of OpenAI’s, Anthropic’s or Google’s APIs, with no training of their own. These products may be profitable in the short term, but they depend entirely on whoever is at the frontier and vanish the moment those companies change pricing, usage policy or contract terms. Only with a public push of this kind can we build the technical workforce capable of doing pre-training from scratch and ensure that Brazil has alternative access to frontier AI, rather than negotiating from a structurally weak position with big AI companies when the country depends on those services and lacks a local alternative.
One of the innovations of this plan is the use of AI for selecting candidates, including for choosing the members of the organizing committee itself. We acknowledge the historical contributions of the Brazilian academic community across many fields. But for a program that has to execute in 1.5 years while competing with the international frontier, we need to be pragmatic: selection should favor those who, right now, are producing cutting-edge results in deep learning. Objective criteria applied by LLMs over a public rubric offer, in practice, more transparency and less room for bias than a process run by closed committees, and the cost of a wrong call is high: a poorly trained model can consume the entire budget without anyone learning anything.
Three-phase structure
Figure 8: three-phase structure. At each transition, the number of teams falls and the per-team funding grows. Totals per phase: Phase 1: R$ 80M (20 × R$ 4M), Phase 2: R$ 96M (8 × R$ 12M), Phase 3: R$ 90M (3 × R$ 30M). Total program budget: R$ 266M over 1.5 years.
Total program cost: R$ 266 million. For context, this is about one quarter of the R$ 1 billion originally proposed by the PBIA (Brazilian AI Plan) for the training of a national LLM.
The R$ 4M per team in Phase 1 was calculated assuming 32 B200 GPUs per team (at US$ 5/hour, exchange rate R$ 5 per US$) running for 6 months, the current on-demand neocloud price. But each team is free to spend the money as it sees fit.
And this freedom matters, because not every team needs to concentrate the budget on compute. Some teams argue, for example, that a pre-training corpus curated by linguists, smaller in scale but of much higher quality than web data, can produce a frontier-competitive model with far less compute. Others bet on alternative architectures, on data synthesis, or on human curation of SFT and RL tasks. None of these hypotheses currently has consensus in the literature, and that is precisely why Phase 1 is the right place to test them: with 20 teams pursuing potentially distinct strategies, the benchmark results themselves will tell us, empirically, which combination of compute, data and algorithm delivers more value per real invested. Forcing every team into a single recipe would mean giving up that information.
Each phase lasts 6 months, totaling 1.5 years of project. Why so short? Keeping the timeline tight, as in the South Korean program, prevents free riders who would use public money to learn neural networks from scratch. If you don’t know anything and somehow got selected by luck, you’re very unlikely to rank among the top 8 teams that advance to the second phase. But if you do, great: good for everyone.
Selection criteria
Eligibility. Before the scored criteria, there is an eligibility filter. The applicant team must meet at least one of the following two conditions:
- be formally affiliated with a Brazilian institution (university, research institute, company or startup with an active Brazilian CNPJ); or
- be an international company whose technical team for the project has at least half of its members being Brazilian or having lived in Brazil for at least two years.
The rationale is straightforward: the program is funded with Brazilian public money to build AI capacity in Brazil. It makes sense to ensure the knowledge, the team and the intellectual property produced stay in the country.
Selection will be automated, using three frontier-LLM judges to reduce human bias. The main criteria:
- Per-capita publications of the team in the deep learning area. Candidates submit their list of papers, and an open-weights LLM with an open prompt decides whether each paper is a deep-learning paper. Papers older than 10 years do not count. The reason is simple and pragmatic: the program has to execute in 1.5 years, in parallel with commercial models that have been retrained every few months. Selection should favor teams whose recent output (papers, code, open models) demonstrates command of the state of the art. Results consolidated over a decade ago, while valuable in other contexts, are a weak proxy for the ability to compete at today’s deep learning frontier.
- Per-capita citations of the team in deep-learning papers, using the same LLM-based classification method.
- Stars on open-source software published on GitHub (or similar) in the deep-learning area.
- Downloads of open models and/or datasets published on Hugging Face or equivalent repositories.
- Other evidence of practical deep-learning experience. The LLM judges will assess, for example, whether the system described actually involves neural-network training (prompt engineering does not count) or rigorous measurement of AI systems.
Important: evidence for the items above will only be valid if produced by May 2026. This prevents participants from flooding the system in the final month with material aimed at improving their ranking. We want researchers and developers with a proven track record. The program does not intend to deliver R$ 4M to teams without prior neural-network training experience. The goal is to support those who, over the last several years, have consistently produced high-quality work in the area.
Advancing between phases
Each Phase-1 team must produce:
- An original benchmark of their own, with a single 0-to-100 metric, in which the score gap between Llama-2-7B and DeepSeek V4 is at least 30 points. This rule rules out the two classic extremes that make a benchmark useless: too easy, where virtually every model scores near 100 and we can’t separate real capability (think two-digit addition: even old models solve it perfectly and the benchmark saturates); and too hard, where the benchmark sits so far above the state of the art that virtually every model scores near zero, and we still can’t distinguish who is improving. In either case the benchmark has no discriminative power: the metric fails to differentiate generations or training quality. Requiring a 30-point gap between a 2023 model and a 2026 model ensures the benchmark measures something that is actually evolving with the state of the art.
- Results on 10 public benchmarks chosen by the organizing committee, covering topics such as tool use, knowledge about Brazil, Portuguese essay writing, code-task solving, math problem solving, and tasks that benefit citizens or the country’s development. These benchmarks can be in any language and the committee should prioritize evaluations already established in public leaderboards, such as Artificial Analysis, ensuring comparability with the international state of the art.
At the end of Phase 1, the models of the 20 teams are evaluated on the 20 original benchmarks produced by the teams themselves plus the 10 public benchmarks chosen by the committee. Each team’s final score is the sum of its performance across these 30 benchmarks. The top 8 teams by total score advance to Phase 2.
The same logic applies to the transition from Phase 2 to Phase 3: each of the 8 Phase-2 teams produces a new original benchmark (8 in total), which are added to a new set of 10 public benchmarks chosen by the committee. The top 3 teams by total score advance to Phase 3.
Prize for finalists
To close the loop between initial public investment and the commercial sustainability of the teams, we propose that the top two teams at the end of Phase 3 have priority in contracts to serve AI models to SERPRO and other federal-government institutions. The public sector is today one of the largest potential consumers of AI in the country, spanning the Judiciary, audit and oversight bodies, public health, the Federal Revenue, defense and several regulatory agencies, and has a legitimate need for sovereignty over the models that process sensitive citizen data.
Ensuring that the winning teams find a ready-made market when leaving the program turns the initial public investment into recurring demand. The government funds the development of technical capacity and then uses that capacity in its own systems, rather than remaining dependent on foreign providers. This is the same virtuous cycle that sustains the Chinese and American AI industries: public capital (defense, science, infrastructure) anchors the first generations, and the private market funds the next ones.
Code confidentiality and auditing
An important design decision: teams’ training code and data-selection/curation pipelines do not need to be public. They remain private, protected as the team’s intellectual property. What changes is that these artifacts will be audited under confidentiality by the organizing committee at the end of each phase, with two objectives:
- Confirm the team has real command of the training stack. The audit verifies that there is a functional in-house code base for pre-training, SFT and RL, and that data was effectively curated by the team, not outsourced or copied without understanding.
- Enable independent reproduction. An external auditor, under NDA, must be able to reproduce the numbers the team reports on the benchmarks using the audited code and data. If reproduction fails by a significant margin, the team loses points or is disqualified.
Choosing private code over public release is deliberate and has a concrete reason: it enables participation by more mature LLM-training companies and institutions. Maritaca, for example, has already invested millions developing the Sabiá-family pipeline and would not be willing to release that intellectual property as a condition for joining the program. If we forced open publication of all training code, the most likely consequence would be to push away exactly the players with the most accumulated technical capacity, and attract only teams with little prior experience, who have less to lose by opening their work. The balance chosen, auditing with confidentiality, keeps the technical bar high without forcing serious companies to give up years of private investment.
There is also an economic-sustainability dimension that reinforces this choice. By not requiring teams to open their code, we create the conditions for them to evolve into sustainable companies in the long run: the training pipeline becomes intellectual property and a competitive differentiator, just as it works for OpenAI, Anthropic, Google and DeepSeek. If we forced full openness, that differentiator disappears, and no team would put in its best effort knowing that, the day after the project ends, a competitor could reappear simply by re-running the public recipe. This logic also acknowledges a structural fact: AI development is a continuous process and cannot be funded by the government indefinitely. The initial public investment is necessary for Brazil to have its first generation of models trained from scratch, but subsequent generations need to be sustained by private initiative and the companies’ own revenue, of the teams that survive the program.
Appeals
Any team that feels unfairly judged by the LLMs, whether in the initial pre-selection or in the phase transitions, may file an appeal with the organizing committee. The appeal must objectively point out where the automated judgment went wrong: criterion misapplied, evidence ignored, or inconsistency among the three LLM judges. The committee, defined in the next section with objective criteria, will perform the human review and decide. Committee decisions are final.
Organizing committee
The committee will be formed by people who meet the following requirements:
- More than 2,000 citations on Google Scholar in deep-learning-related papers, considering only the last 5 years.
- Have contributed to open-weights models, GitHub code, or impactful public datasets/benchmarks.
The 5-year window is deliberate and aims to ensure the committee is composed of people with relevant current production in the area. This is not about dismissing prior contributions, and it’s worth noting that many researchers active today come precisely from the Brazilian academic tradition. The point is practical: deep learning is undergoing rapid reconfiguration, with techniques and architectures shifting every 12 to 24 months. Decisions about who should receive resources to train frontier LLMs call for evaluators whose recent practice keeps them synchronized with that pace. The window reduces the risk, recurrent in Brazilian public tenders, of sensitive technical decisions being made by evaluators removed from current practice.
In short: we want evaluators with recent output in deep learning.
Phase-1 starting point and expectations
It’s worth making a distinction here that is often confused in public debate:
- Open-weights: the company releases only the weights of an already-trained model. You can run it, finetune it, or distill from it, but you don’t have access to the pre-training data, training code, or data curation pipeline. This is the case for Llama, Qwen, DeepSeek, Mistral.
- Open-source (the real thing): the organization releases the whole package. Weights + pre-training data + training code + curation pipeline. You can reproduce the model from scratch, modify recipes, and understand why it behaves the way it does. The current reference example is OLMo 3 from the Allen Institute for AI, which released data, preprocessing scripts, pre-training scripts, SFT and RL scripts, and all execution logs.
The 20 teams selected in Phase 1 are encouraged to build on open-source recipes like OLMo 3 rather than reinventing the entire pipeline. The knowledge accumulated by the community over the past few years is literally available in public repositories.
Given the R$ 4M budget and 6-month timeline for each Phase-1 team, it’s important to calibrate expectations: Phase-1 teams will not produce frontier models. They’ll produce small models, likely on the order of a few billion parameters, trained on modest corpora. The goal of this phase is not to deliver a product, it’s to learn to train: master the pre-training, SFT and RL cycle, internalize the data curation pipeline, find infrastructure bottlenecks, and produce a benchmark of their own that demonstrates the team knows how to measure what matters.
The accumulated knowledge is what enables the best teams from Phase 1 to enter Phase 2 with a working pipeline, and use the larger budget (R$ 12M) to take a step up in model size and data quality. The same applies to the transition from Phase 2 to Phase 3 (R$ 30M per team). It’s a cumulative process: each phase is building the technical workforce that will sustain Brazil’s AI industry for the next 5 to 10 years.
Why competitive, not collaborative
It’s worth making explicit a point that distinguishes this plan from other proposals currently being debated in government. The proposal here is, at its core, competitive. By contrast, collaborative approaches have been floated, in which a small group of large companies and institutions would be assembled into a single consortium to develop the national LLM.
In our view, the collaborative model tends to fail for the very reasons that make it politically attractive. The first problem is the absence of competitive pressure: when a team knows it is the only one executing the project, there is no cost for delay, for below-expected results, or for the conservative technical decision. In the plan we propose, Phase 1 starts with 20 teams competing for 8 spots in Phase 2, and that funnel creates real pressure to deliver.
The second is that coordination becomes ambiguous. When several large institutions enter together, it is hard to define who actually leads, and each partner arrives with its own structure, its senior researchers and its priorities. The typical outcome is a committee instead of a team, and committees tend to be slower and to operate without a clear direction.
The third is that participant selection turns into a political game: in a model with few seats, those who get in are the institutions with the best government access, the most capacity for political articulation and the best connections with decision-makers, not necessarily those with the most technical capability to deliver. Meritocracy is, in practice, the first casualty.
Finally, researchers outside the traditional circuit are left out. With 20 teams in Phase 1, there is room for small groups, newly formed teams and researchers outside the most visible institutions to apply on merit; a collaborative model, with 1 or 2 large consortia, closes that door.
The competitive model is not comfortable for participants, and that is a feature, not a side effect. The international AI industry is one of the most competitive on the planet. Brazil will not train relevant LLMs in a protected environment where no one is eliminated.
Comments, criticism and suggestions (on criteria, numbers, areas that should be included, or objections to the plan) are welcome: please write to info@maritaca.ai.